HammerDB already has 2 interfaces with which to interface with the commands to build and test databases using the GUI interface or CLI. From HammerDB version 3.2 there is an additional interface that enables HammerDB to run as Web Service. This allows HammerDB to be driven with a REST type client using a HTTP interface to call and retrieve output from the CLI commands. Additional json, rest and huddle packges have been added with which to format and process input and output. This interface can be started using the hammerdbws command at which hammerdb will proceed to listen on a predefined port. (see the documentation for setting the port).
$ ./hammerdbws
HammerDB Web Service v3.2
Copyright (C) 2003-2019 Steve Shaw
Type "help" for a list of commands
The xml is well-formed, applying configuration
Initialized new SQLite in-memory database
Starting HammerDB Web Service on port 8080
Listening for HTTP requests on TCP port 8080
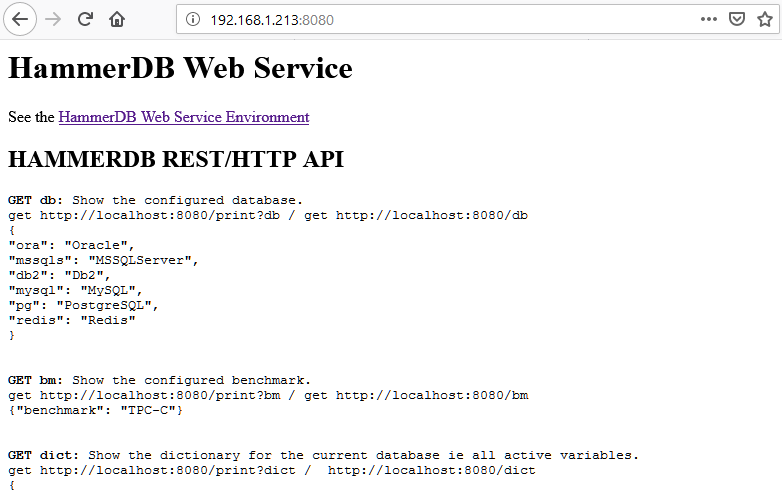
Using a browser to navigate to that port will show the help screen.
It is important to note that scripts written to drive this interface can be written in any language of choice. When using TCL the additional packages provided can be used for formatting. The following test script shows how this interaction can be done also including deliberate errors to demonstrate error handling.
$ more restchk.tcl
#!/bin/sh
#########################################################################
## \
export LD_LIBRARY_PATH=./lib:$LD_LIBRARY_PATH
## \
export PATH=./bin:$PATH
## \
exec ./bin/tclsh8.6 "$0" ${1+"$@"}
########################################################################
set UserDefaultDir [ file dirname [ info script ] ]
::tcl::tm::path add "$UserDefaultDir/modules"
package require rest
package require huddle
puts "TEST DIRECT PRINT COMMANDS"
#clear any existing script
set res [rest::post http://localhost:8080/clearscript "" ]
puts "--------------------------------------------------------"
foreach i {db bm dict script vuconf vucreated vustatus datagen} {
puts "Printing output for $i and converting JSON to text"
set res [rest::get http://localhost:8080/$i "" ]
puts "JSON format"
puts $res
puts "TEXT format"
set res [rest::format_json $res]
puts $res
}
puts "--------------------------------------------------------"
puts "PRINT COMMANDS COMPLETE"
puts "--------------------------------------------------------"
puts "TEST PRINT COMMANDS AS OPTION TO PRINT ie print?dict "
foreach i {db bm dict script vuconf vucreated vustatus datagen} {
puts "Printing output for $i and converting JSON to text"
set res [rest::get http://localhost:8080/print?$i "" ]
puts "JSON format"
puts $res
puts "TEXT format"
set res [rest::format_json $res]
puts $res
}
puts "PRINT COMMANDS COMPLETE"
puts "--------------------------------------------------------"
puts "TEST DISET"
puts "Setting Warehouse Count to 800"
set body { "dict": "tpcc", "key": "count_ware", "value": "800" }
set res [rest::post http://localhost:8080/diset $body ]
puts "Setting password to new password"
set body { "dict": "tpcc", "key": "tpcc_pass", "value": "new_password" }
set res [rest::post http://localhost:8080/diset $body ]
puts "Setting password error 1 invalid string"
set body { "dict": "tpcc", "ke }
set res [rest::post http://localhost:8080/diset $body ]
puts $res
puts "Setting password error 2 invalid number of arguments"
set body { "dict": "tpcc" }
set res [rest::post http://localhost:8080/diset $body ]
puts $res
puts "Setting password error 3 invalid key"
set body { "dict": "tpcc", "key": "tpcds_pass", "value": "new_password" }
set res [rest::post http://localhost:8080/diset $body ]
puts $res
puts "Setting password error 4 invalid string"
set body { "dict": "tpcfg", "key": "tpcds_pass", "value": "new_password" }
set res [rest::post http://localhost:8080/diset $body ]
puts $res
puts "Setting Driver Script"
set body { "dict": "tpcc", "key": "ora_driver", "value": "timed" }
set res [rest::post http://localhost:8080/diset $body ]
puts $res
puts "Setting Driver Script Error"
set body { "dict": "tpcc", "key": "ora_driver", "value": "timid" }
set res [rest::post http://localhost:8080/diset $body ]
puts $res
puts "Clearscript"
set res [rest::post http://localhost:8080/clearscript "" ]
puts $res
puts "Loadscript"
set res [rest::post http://localhost:8080/loadscript "" ]
puts $res
set res [rest::get http://localhost:8080/print?script "" ]
#uncomment to print script
#puts $res
puts "Script in TEXT format"
set res [rest::format_json $res]
#uncomment to print script
#puts $res
puts "VU Status"
set res [rest::get http://localhost:8080/vustatus "" ]
puts $res
puts "Testing dbset"
set body { "db": "mssqs" }
set res [ rest::post http://localhost:8080/dbset $body ]
puts $res
puts "Testing dbset"
set body { "dx": "mssqls" }
set res [ rest::post http://localhost:8080/dbset $body ]
puts $res
puts "Testing dbset"
set body { "db": "pg" }
set res [ rest::post http://localhost:8080/dbset $body ]
puts $res
puts "Testing dbset"
set body { "bm": "TPC-X" }
set res [ rest::post http://localhost:8080/dbset $body ]
puts $res
puts "Testing dbset"
set body { "bm": "TPC-H" }
set res [ rest::post http://localhost:8080/dbset $body ]
puts $res
puts "Testing vuset"
set body { "vuxx": "109" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
puts "Testing vuset"
set body { "vu": "10" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
puts "Testing dgset"
set body { "directory": "/home/oracle" }
set res [ rest::post http://localhost:8080/dgset $body ]
puts $res
puts "Testing Custom Script : Open File convert to JSON and post"
set customscript "testscript.tcl"
set _ED(file) $customscript
if {$_ED(file) == ""} {return}
if {![file readable $_ED(file)]} {
puts "File \[$_ED(file)\] is not readable."
return
}
if {[catch "open \"$_ED(file)\" r" fd]} {
puts "Error while opening $_ED(file): \[$fd\]"
} else {
set _ED(package) "[read $fd]"
close $fd
}
set huddleobj [ huddle compile {string} "$_ED(package)" ]
set jsonobj [ huddle jsondump $huddleobj ]
set body [ subst { {"script": $jsonobj}} ]
set res [ rest::post http://localhost:8080/customscript $body ]
puts $res
set res [rest::get http://localhost:8080/print?script "" ]
#uncomment to print script
#puts $res
puts "Custom Script in TEXT format"
set res [rest::format_json $res]
#uncomment to print script in text
#puts $res
puts "Testing vuset"
set body { "vu": "5" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
puts "Testing vucreate"
set res [ rest::post http://localhost:8080/vucreate "" ]
puts $res
puts "Testing vucreate"
set res [ rest::post http://localhost:8080/vucreate "" ]
puts $res
puts "VU Status after create"
set res [rest::get http://localhost:8080/vustatus "" ]
puts $res
puts "Testing vudestroy"
set res [ rest::post http://localhost:8080/vudestroy "" ]
puts $res
puts "VU Status after destroy"
set res [rest::get http://localhost:8080/vustatus "" ]
puts $res
Running this script shows the following output.
$ ./restchk.tcl
TEST DIRECT PRINT COMMANDS
--------------------------------------------------------
Printing output for db and converting JSON to text
JSON format
{
"ora": "Oracle",
"mssqls": "MSSQLServer",
"db2": "Db2",
"mysql": "MySQL",
"pg": "PostgreSQL",
"redis": "Redis"
}
TEXT format
ora Oracle mssqls MSSQLServer db2 Db2 mysql MySQL pg PostgreSQL redis Redis
Printing output for bm and converting JSON to text
JSON format
{"benchmark": "TPC-C"}
TEXT format
benchmark TPC-C
Printing output for dict and converting JSON to text
JSON format
{
"connection": {
"system_user": "system",
"system_password": "manager",
"instance": "oracle",
"rac": "0"
},
"tpcc": {
"count_ware": "1",
"num_vu": "1",
"tpcc_user": "tpcc",
"tpcc_pass": "tpcc",
"tpcc_def_tab": "tpcctab",
"tpcc_ol_tab": "tpcctab",
"tpcc_def_temp": "temp",
"partition": "false",
"hash_clusters": "false",
"tpcc_tt_compat": "false",
"total_iterations": "1000000",
"raiseerror": "false",
"keyandthink": "false",
"checkpoint": "false",
"ora_driver": "test",
"rampup": "2",
"duration": "5",
"allwarehouse": "false",
"timeprofile": "false"
}
}
TEXT format
connection {system_user system system_password manager instance oracle rac 0} tpcc {count_ware 1 num_vu 1 tpcc_user tpcc tpcc_pass tpcc tpcc_def_tab tpcctab tpcc_ol_tab tpcctab tpcc_def_temp temp partition false hash_clusters false tpcc_tt_compat false total_iterations 1000000 raiseerror false keyandthink false checkpoint false ora_driver test rampup 2 duration 5 allwarehouse false timeprofile false}
Printing output for script and converting JSON to text
JSON format
{"error": {"message": "No Script loaded: load with loadscript"}}
TEXT format
error {message {No Script loaded: load with loadscript}}
Printing output for vuconf and converting JSON to text
JSON format
{
"Virtual Users": "1",
"User Delay(ms)": "500",
"Repeat Delay(ms)": "500",
"Iterations": "1",
"Show Output": "1",
"Log Output": "0",
"Unique Log Name": "0",
"No Log Buffer": "0",
"Log Timestamps": "0"
}
TEXT format
{Virtual Users} 1 {User Delay(ms)} 500 {Repeat Delay(ms)} 500 Iterations 1 {Show Output} 1 {Log Output} 0 {Unique Log Name} 0 {No Log Buffer} 0 {Log Timestamps} 0
Printing output for vucreated and converting JSON to text
JSON format
{"Virtual Users created": "0"}
TEXT format
{Virtual Users created} 0
Printing output for vustatus and converting JSON to text
JSON format
{"Virtual User status": "No Virtual Users found"}
TEXT format
{Virtual User status} {No Virtual Users found}
Printing output for datagen and converting JSON to text
JSON format
{
"schema": "TPC-C",
"database": "Oracle",
"warehouses": "1",
"vu": "1",
"directory": "\/tmp\""
}
TEXT format
schema TPC-C database Oracle warehouses 1 vu 1 directory /tmp\"
--------------------------------------------------------
PRINT COMMANDS COMPLETE
--------------------------------------------------------
TEST PRINT COMMANDS AS OPTION TO PRINT ie print?dict
Printing output for db and converting JSON to text
JSON format
{
"ora": "Oracle",
"mssqls": "MSSQLServer",
"db2": "Db2",
"mysql": "MySQL",
"pg": "PostgreSQL",
"redis": "Redis"
}
TEXT format
ora Oracle mssqls MSSQLServer db2 Db2 mysql MySQL pg PostgreSQL redis Redis
Printing output for bm and converting JSON to text
JSON format
{"benchmark": "TPC-C"}
TEXT format
benchmark TPC-C
Printing output for dict and converting JSON to text
JSON format
{
"connection": {
"system_user": "system",
"system_password": "manager",
"instance": "oracle",
"rac": "0"
},
"tpcc": {
"count_ware": "1",
"num_vu": "1",
"tpcc_user": "tpcc",
"tpcc_pass": "tpcc",
"tpcc_def_tab": "tpcctab",
"tpcc_ol_tab": "tpcctab",
"tpcc_def_temp": "temp",
"partition": "false",
"hash_clusters": "false",
"tpcc_tt_compat": "false",
"total_iterations": "1000000",
"raiseerror": "false",
"keyandthink": "false",
"checkpoint": "false",
"ora_driver": "test",
"rampup": "2",
"duration": "5",
"allwarehouse": "false",
"timeprofile": "false"
}
}
TEXT format
connection {system_user system system_password manager instance oracle rac 0} tpcc {count_ware 1 num_vu 1 tpcc_user tpcc tpcc_pass tpcc tpcc_def_tab tpcctab tpcc_ol_tab tpcctab tpcc_def_temp temp partition false hash_clusters false tpcc_tt_compat false total_iterations 1000000 raiseerror false keyandthink false checkpoint false ora_driver test rampup 2 duration 5 allwarehouse false timeprofile false}
Printing output for script and converting JSON to text
JSON format
{"error": {"message": "No Script loaded: load with loadscript"}}
TEXT format
error {message {No Script loaded: load with loadscript}}
Printing output for vuconf and converting JSON to text
JSON format
{
"Virtual Users": "1",
"User Delay(ms)": "500",
"Repeat Delay(ms)": "500",
"Iterations": "1",
"Show Output": "1",
"Log Output": "0",
"Unique Log Name": "0",
"No Log Buffer": "0",
"Log Timestamps": "0"
}
TEXT format
{Virtual Users} 1 {User Delay(ms)} 500 {Repeat Delay(ms)} 500 Iterations 1 {Show Output} 1 {Log Output} 0 {Unique Log Name} 0 {No Log Buffer} 0 {Log Timestamps} 0
Printing output for vucreated and converting JSON to text
JSON format
{"Virtual Users created": "0"}
TEXT format
{Virtual Users created} 0
Printing output for vustatus and converting JSON to text
JSON format
{"Virtual User status": "No Virtual Users found"}
TEXT format
{Virtual User status} {No Virtual Users found}
Printing output for datagen and converting JSON to text
JSON format
{
"schema": "TPC-C",
"database": "Oracle",
"warehouses": "1",
"vu": "1",
"directory": "\/tmp\""
}
TEXT format
schema TPC-C database Oracle warehouses 1 vu 1 directory /tmp\"
PRINT COMMANDS COMPLETE
--------------------------------------------------------
TEST DISET
Setting Warehouse Count to 800
Setting password to new password
Setting password error 1 invalid string
{"error": {"message": "Not a valid JSON string: '{ \"dict\": \"tpcc\", \"ke }'"}}
Setting password error 2 invalid number of arguments
{"error": {"message": "Incorrect number of parameters to diset dict key value"}}
Setting password error 3 invalid key
{"error": {"message": "Dictionary \"tpcc\" for Oracle exists but key \"tpcds_pass\" doesn't"}}
Setting password error 4 invalid string
{"error": {"message": "Dictionary \"tpcfg\" for Oracle does not exist"}}
Setting Driver Script
{"success": {"message": "Set driver script to timed, clearing Script, reload script to activate new setting"}}
Setting Driver Script Error
{"error": {"message": "Error: Driver script must be either \"test\" or \"timed\""}}
Clearscript
{"success": {"message": "Script cleared"}}
Loadscript
{"success": {"message": "script loaded"}}
Script in TEXT format
VU Status
{"Virtual User status": "No Virtual Users found"}
Testing dbset
{"error": {"message": "Unknown prefix mssqs, choose one from ora mssqls db2 mysql pg redis"}}
Testing dbset
{"error": {"message": "Invalid option to dbset key value"}}
Testing dbset
{"success": {"message": "Database set to PostgreSQL"}}
Testing dbset
{"error": {"message": "Unknown benchmark TPC-X, choose one from TPC-C TPC-H"}}
Testing dbset
{"success": {"message": "Benchmark set to TPC-H for PostgreSQL"}}
Testing vuset
{"error": {"message": "Invalid option to vuset key value"}}
Testing vuset
{"success": {"message": "Virtual users set to 10"}}
Testing dgset
{"success": {"message": "Set directory to \/tmp for data generation"}}
Testing Custom Script : Open File convert to JSON and post
{"success": {"message": "Set custom script"}}
Custom Script in TEXT format
Testing vuset
{"success": {"message": "Virtual users set to 5"}}
Testing vucreate
{"success": {"message": "6 Virtual Users Created with Monitor VU"}}
Testing vucreate
{"error": {"message": "Virtual Users exist, destroy with vudestroy before creating"}}
VU Status after create
{"Virtual User status": "1 {WAIT IDLE} 2 {WAIT IDLE} 3 {WAIT IDLE} 4 {WAIT IDLE} 5 {WAIT IDLE} 6 {WAIT IDLE}"}
Testing vudestroy
{"success": {"message": "vudestroy success"}}
VU Status after destroy
{"Virtual User status": "No Virtual Users found"}
When the environment is configured you can build schemas and run workloads with the same commands used for the CLI, for example:
set res [rest::post http://localhost:8080/buildschema "" ]
set res [rest::post http://localhost:8080/vurun "" ]
The key difference is that output is now stored in a job format that can be retrieved at a later point. An example is shown where a build generates a jobid.
{"success": {"message": "Building 5 Warehouses with 6 Virtual Users, 5 active + 1 Monitor VU(dict value num_vu is set to 5): JOBID=5D23464E58D203E273738333"}}
That is then used to query the status of the build.
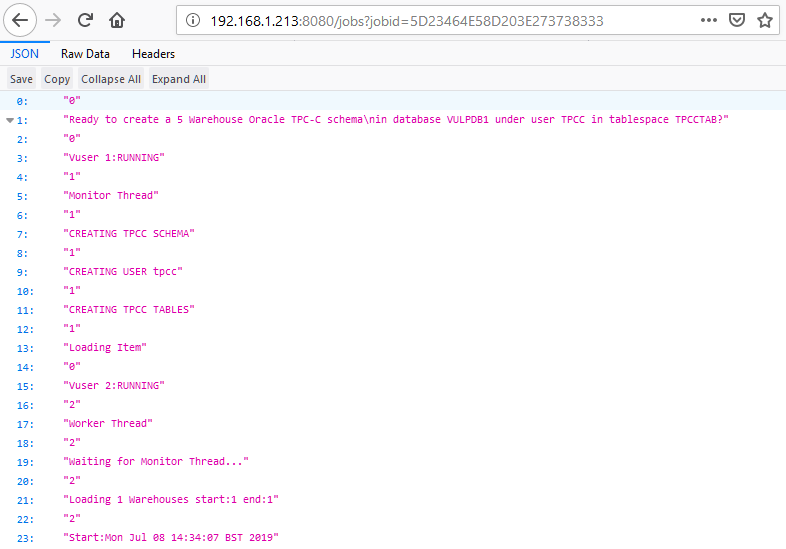
The output is stored in a SQLite database that by default runs in in-memory mode that is not persistent over restarts, however it can be configured to use a permanent database.
It is not intended for the web service to replace the GUI or CLI environments that still prove the most popular way to run HammerDB, however the aim is to provide an additional way that HammerDB can be integrated into tests in in cloud environments particular.