This example for generating the dataset uses SQL Server on Windows, however the process is identical when creating data on Linux. Firstly create an empty directory that is writable for the user running HammerDB and does not contain any existing generated files. HammerDB will not overwrite existing generated files.

This is a good point to validate how much free space is available in the directory. HammerDB will not check that enough free space exists in the file system before generating data. From the benchmark menu select your chosen database and workload. Note that it is particularly important that you select the correct database and workload for your environment before generating the data. The data generated is different between different databases and workloads. For example for optimization purposes the columns may be ordered differently between different databases. The data is generated in column order for the way that HammerDB generates the schema and data such as time and date formats may be different. Errors will result from loading the data generated for one database in another without modification.
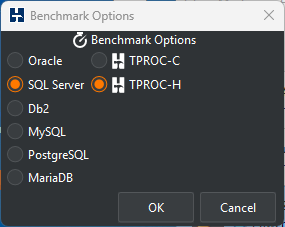
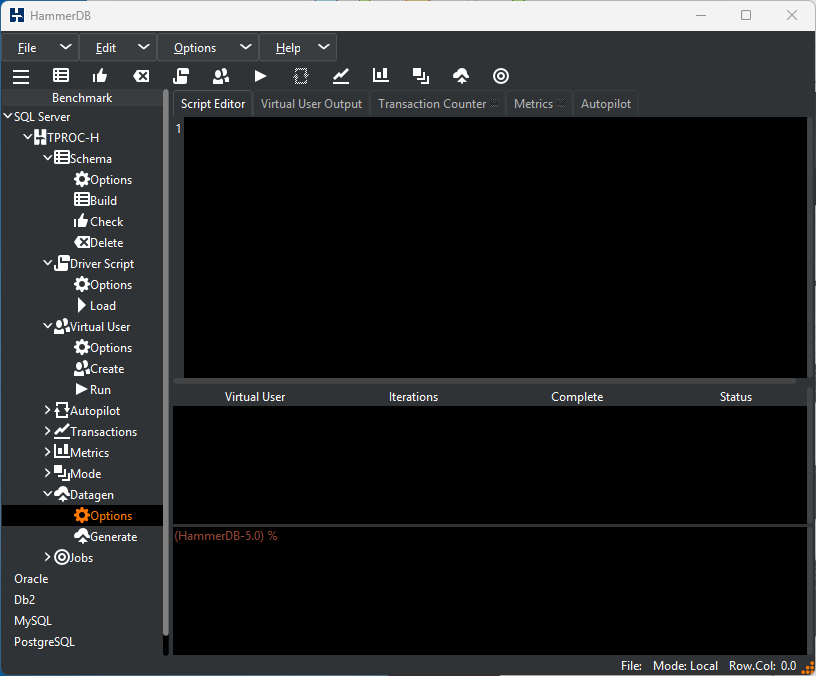
Under the benchmark or Options menus select Datagen and Options
Depending upon whether you have selected a TPROC-C or TPROC-H benchmark under the benchmark options the dialog will be different. For the TPROC-H options select the Scale Factor, the directory that you have pre-created and the number of Virtual Users to generate the schema.
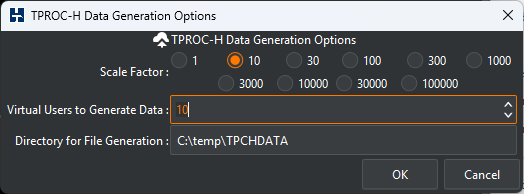
The data generation offers linear scalability with the key limit on performance being the number of CPU cores/threads on the system. Each virtual user will use 100% of an available core/thread and therefore it should be clear that creating more virtual users than available cores/threads is non-productive. Additionally creating the same number of virtual users as cores/threads will drive CPU utilisation to 100% - therefore select the number of Virtual Users equivalent to the available capacity on the system. Similarly it should also be clear that the time to create a data set is dependent on the number of available cores/threads – a 4 socket or above server with hundreds of cores/threads will be able to generate data considerably more quickly than a single socket PC or laptop. Finally bear in mind that each virtual user will generate a subsection of the data for tables. For example selecting 10 virtual users will generate 10 separate files to load each table. This approach enables both flexibility and scalability in both generating the data but also uploading generated files to the cloud and loading data in parallel.
When the chosen values have been selected choose and click the Generate button or Generate menu option.
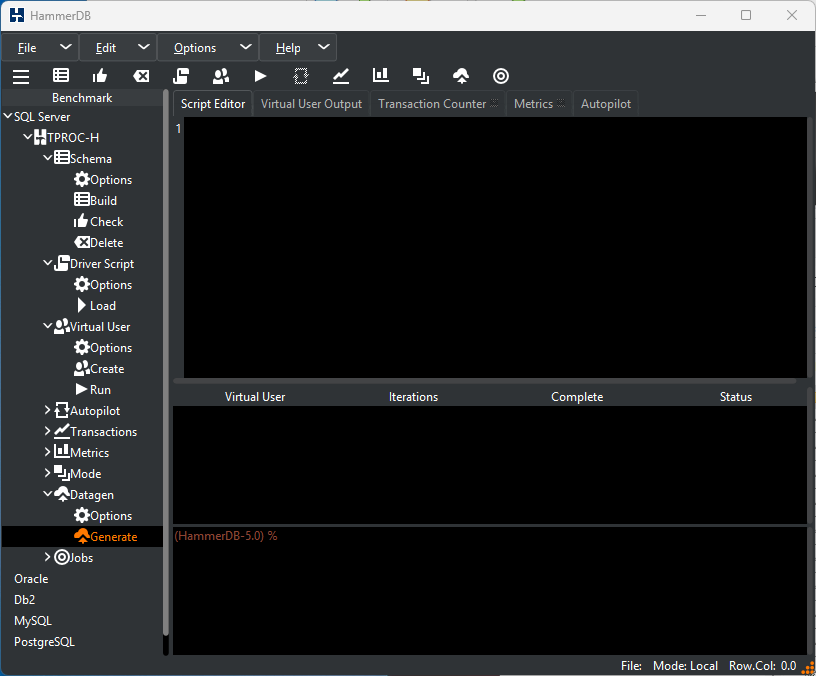
This displays the Generate Data confirmation. Click Yes.
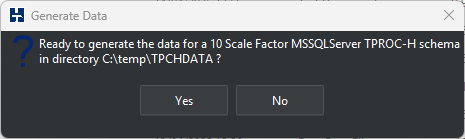
HammerDB will begin to generate the chosen schema in parallel.
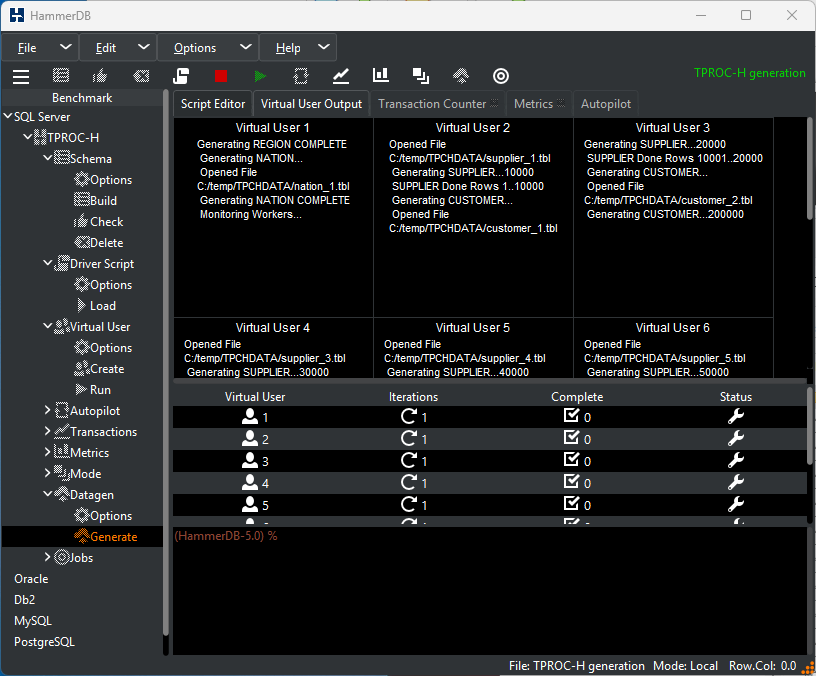
HammerDB requires no further intervention to generate the data for the required schema.
You may also view the data with a text editor to see that the generated data is delimited by a pip character ie “|” and intended NULL values are represented by blank or empty data.

Data is now generated and you are ready to proceed to creating a schema and loading the data. It should be clear that once you have created a chosen data set then you are able to reuse and reload that dataset multiple times and therefore HammerDB enables a quick way to generate all of the test data that you require. It is also important to note that in some cases databases will support compressing data with tools such as zip or gzip prior to loading and therefore if you have a large dataset to upload then investigating whether this is an option for your database is a worthwhile task.