
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications”. However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
So who is right? Could you really be better off not being better informed? This post addresses some of the opinions around database benchmarking and gives the top 5 reasons why industry standard benchmarking is important and should be an essential foundation of your database engineering strategy.
Note that the main developer of HammerDB is Intel employee (#IAMINTEL) however HammerDB is a personal open source project and any opinions are specific to the context of HammerDB as an independent personal project and are not related to Intel in any way.
1. Repeatability
The first known usage of the term benchmark stems from surveying in the early 1800’s to mark the border between North and South Carolina. in this context a bench is a mark in typically a stone structure to place a level staff to make sure that accurate measurements can be made from the same position at some point in time in the future. This initial usage of the term gives us insight into the importance of benchmarks today that can be summed in a single word “Repeatability”. Just like the original context of the term benchmark the single most important and overriding factor of any database benchmark is that if you run the same test on exactly the same configuration, (allowing for a small margin or error) you get the same result. If you change something and re-run the same test the difference in the results can be attributed to the changes you made. Consequently over time you have a reference point “set in stone” from which future changes can be measured by running the same test. That is why we run a workload designed exactly for this purpose as it gives us a “benchmark”.
2. Scalability
Benchmarks are nothing like your real applications, and that’s actually good thing because unlike your application a good benchmark application like HammerDB has been designed to scale. “Scalability” is a product of both the benchmarking application itself (See the post on HammerDB Architecture to see how it scales implementing multiple virtual users as threads) as well as the benchmarking workload (The TPC benchmarks that HammerDB uses have been designed specifically for this purpose and proven over decades to scale). With a proven application and workload that delivers repeatability, you can then determine the capabilities of the components that you want to assess as noted in the introduction such as processing architecture and speed, memory, storage subsystems and the database engine.
For example the following chart (with the actual data removed for the reasons described further in this post) shows the HammerDB TPC-C workload run against the same database on different processing architectures (grouped by colour) and speed with the most recent at the top. As the chart shows because we know that both HammerDB and the implementation of the TPC-C workload scales then we can determine that with this particular database engine both the software and hardware scales as well.
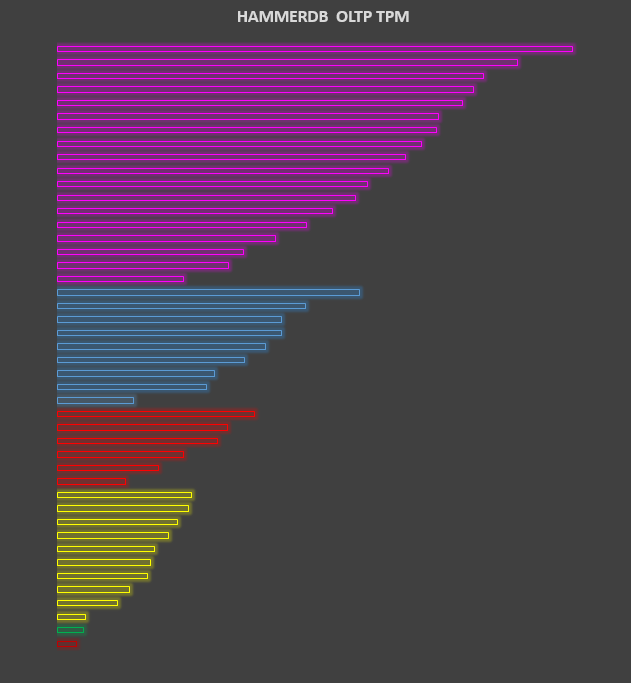
If you only test your own application (and if you have more than one application which one will you use for benchmarking?) can you be sure that it scales? if not how will you determine the optimal deployment platform for those applications (if you don’t know whether your application scales in the first place?) The answer is to run a proven application and workload to provide those quantifiable and repeatable results. With a chart such as the one above you can then compare results from your own application tests to determine whether they scale as well.
3. Security
So if you have compared the results of your own application and it is repeatable and scalable then why not use that for all of your benchmarking going forward? A key reason is “Security” of the data that you are going to use to test for your benchmarks. When running HammerDB you can generate and insert data “on the fly” or generate flat files and upload them for bulk inserting. In all cases this is random data so presents no security challenges. When testing your application however this is a very real consideration. For example when considering moving a database application into the cloud are you going to copy your actual production data into multiple cloud environments for testing? If not are you going to “clean” your data so it does not present a security risk? A benchmarking scenario of testing maintenance jobs is one of the highest risk approaches around. If you are going to restore your production backups onto the new server how can you be sure that this data is safe in transit and completely deleted when the test is complete. Either way there will be a much higher level of security due diligence and hence cost required when using production data. Even if you are confident that your data is secure then you then need a way to accurately simulate your application. HammerDB offers a way to do this for Oracle by the replaying of trace files and there is an excellent series on doing this by House of Brick. However be aware that even such an approach as capturing tracefiles or using similar tools can reveal the data in your application.
4. Portability
Even if you are not particularly concerned about the security of your data for your test strategy, then another disadvantage of only testing your own application is that it is likely to lack “Portability”. This means that if you wish to compare your application running against a different database or operating system then there may be a considerable effort to port the application to multiple new environments just for testing and after establishing functionality there may be considerable tuning effort as well. This is why for example HammerDB offers all functionality equally on both Windows and Linux and was therefore the first benchmarking tool to natively support SQL Server on Linux. HammerDB has been tuned, optimized and tested against all of the databases it supports for high performance to enable you to explore the boundaries of these databases before committing to a full porting strategy for your application. in addition to restrictions on the portability of your own application this also applies to a number of available database benchmarking applications as well. HammerDB provides performance metrics that can be used to compare databases however many benchmarking tools are severely limited being available only on one operating system or supporting only one database. This lack of portability restricts the comparability of your available options at the outset making a non-portable benchmark set is of limited use.
5. Shareability
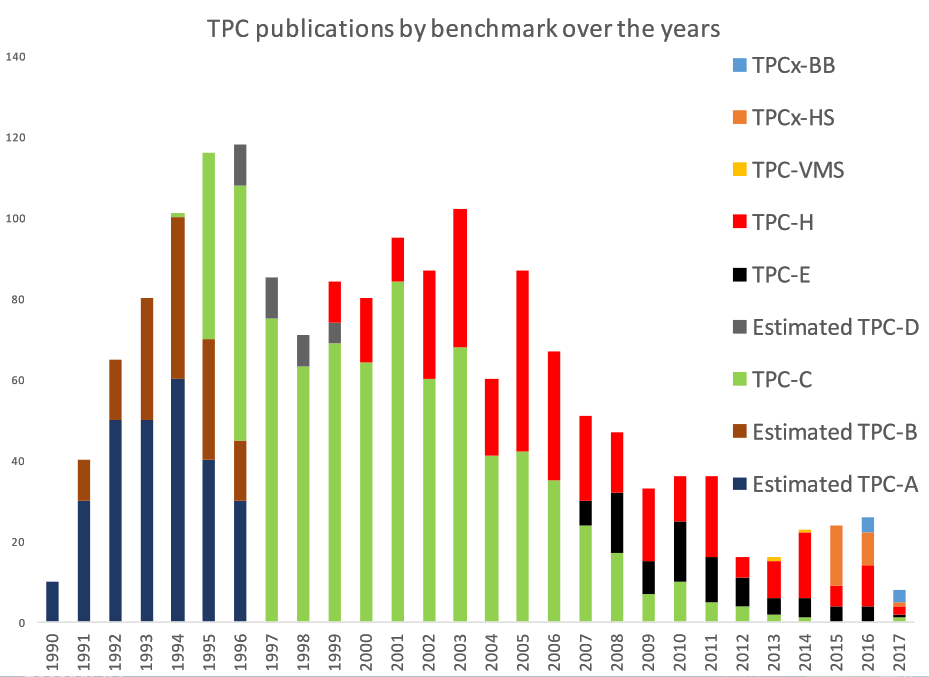
The final and arguably most important reason for running standard benchmarks is one of “Shareability”. There is a significant advantage in running the same repeatable, scalable, secure and portable workload as everyone else with numerous examples shared on the HammerDB website. For example if you want to run SQL Server on AWS there is already an example published by AWS here (Note how the graphs resemble the same scalability as previously described in this article). This is especially important as the number of official published benchmarks has reduced over time as shown in the graph from this presentation on TPC relevance. The TPC workloads are more popular than ever before however the way are published and the information shared has changed dramatically in the era of cloud and social media.
The other side of shareability is the license clause known as the “Dewitt Clause” in some proprietary databases. There are many similar posts and articles on this clause which this post will not repeat apart from stating that database performance information may be less available for some databases compared to others as the license prevents the publication of performance data. It is arguable that in the modern era whether these clauses continue to provide the benefit intended. Nevertheless the restriction of available data means running your own standard benchmarks to gather your own data for private is an essential process for users of these databases.
Summary
So are standard database benchmarks meaningless? Clearly if the team running the benchmarks lacks the sufficient skillset to both correctly run and interpret the workloads then this could be true. Otherwise having a known workload that exercises all of the essential features of a relational database and runs on as varied an environment as possible is invaluable whether you are working in research or engineering and maybe even don’t have your own applications to test or are choosing the optimal hardware and software configurations for a complex production support environment. Either way HammerDB is designed from the outset to help you be better informed and to share this performance information as widely as possible.