Many of the HammerDB TPROC-C workloads have included features to prevent the database doing maintenance tasks for the previous run whilst another run is taking place. This is particularly important when running automated workloads back-back to generate a performance profile for a progressively increasing number of virtual users. An example of this is the “Checkpoint when complete” option for Oracle which will flush all dirty/modified data blocks in the in-memory buffer cache to disk and then switch the logfiles so this will not happen during a subsequent run with database writer activity impacting performance.
History List
With MySQL and MariaDB a key maintenance activity that can impact performance is purging which can be monitored with the history list length with a SQL statement such as follows.
select variable_value from information_schema.global_status where variable_name = 'INNODB_HISTORY_LIST_LENGTH'"
When a workload deletes data from MySQL or MariaDB the row is not deleted straight away and only when it is not needed for read consistency and the referring undo record for the operation is deleted. The history list length that can be queried is the number of undo log pages that contain changes. If the history list length grows too large then a larger number of row versions can impact query performance, however purging to process the undo log pages can also itself impact performance requiring mutex locking. For this reason we have a number of parameters, notably innodb_purge_threads, innodb_purge_batch_size, innodb_max_purge_lag and innodb_max_purge_lag_delay. The number of purge threads and batch size determine how aggressively purging takes place and the purge lag and delay allow throttling of throughput of transactions if the history list grows too large to allow purging to catch up.
It should be clear that if you want to stress a MySQL or MariaDB databases then a workload that includes delete operations is essential to the overall picture and fortunately in the HammerDB workload the DELIVERY stored procedure includes a loop that processes a large number of delete operations and therefore is a great opportunity to test the effectiveness of your purge settings. However until recently the purge parameters have only been able to be changed after a server restart and therefore we haven’t been able to accelerate a purge after a workload has completed. Fortunately with MariaDB this change Make number of purge threads variable dynamic as it suggests makes the configuration dynamic and we can take advantage of this to do a purge to clear the history list after a workload has completed so the purging for one test run does not unduly impact the following run.
In addition to the history list when adding this functionality we can also add similar functionality to write back the dirty buffers in the buffer pool at the same time.
Setting Purge and Write Back
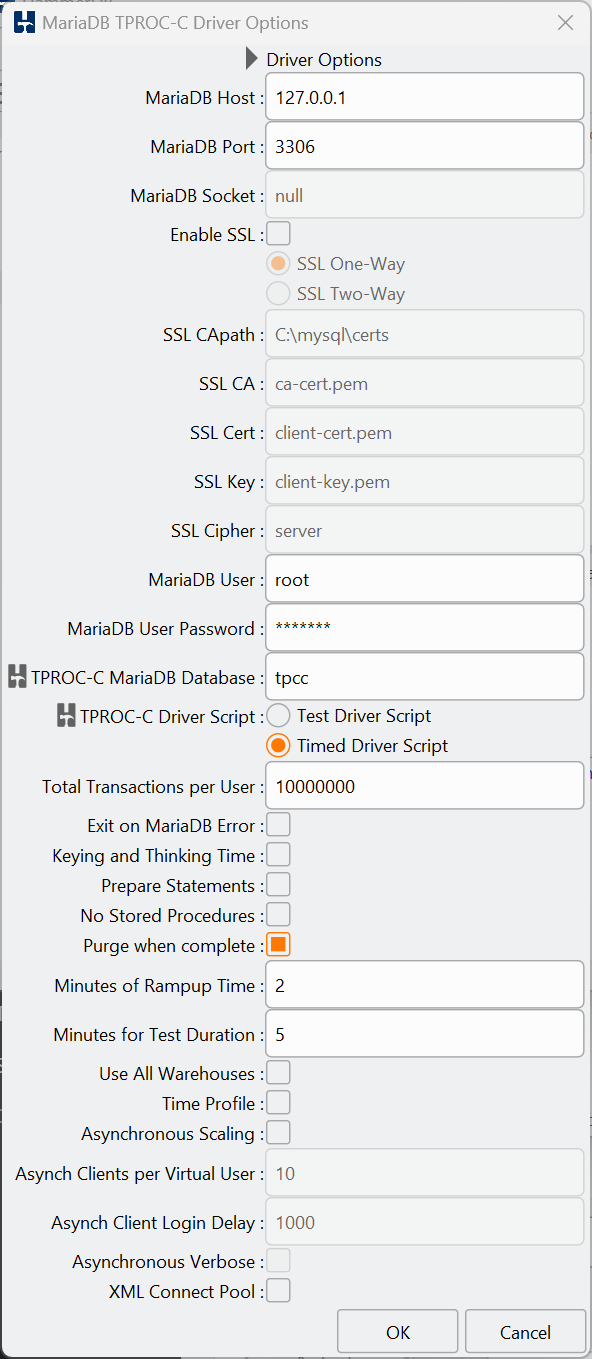
To run the purge and write back after a MariaDB workload you need at least version 10.7.0 of MariaDB when the variables were made dynamic. If you do not have this version HammerDB will report during a run that the settings cannot be made. Otherwise if you have version 10.7.0 or above, in the GUI choose the Purge when complete checkbox in your driver settings.
Or in the CLI set the option maria_purge to true.
tpcc {
maria_count_ware = 30
...
maria_purge = true
}
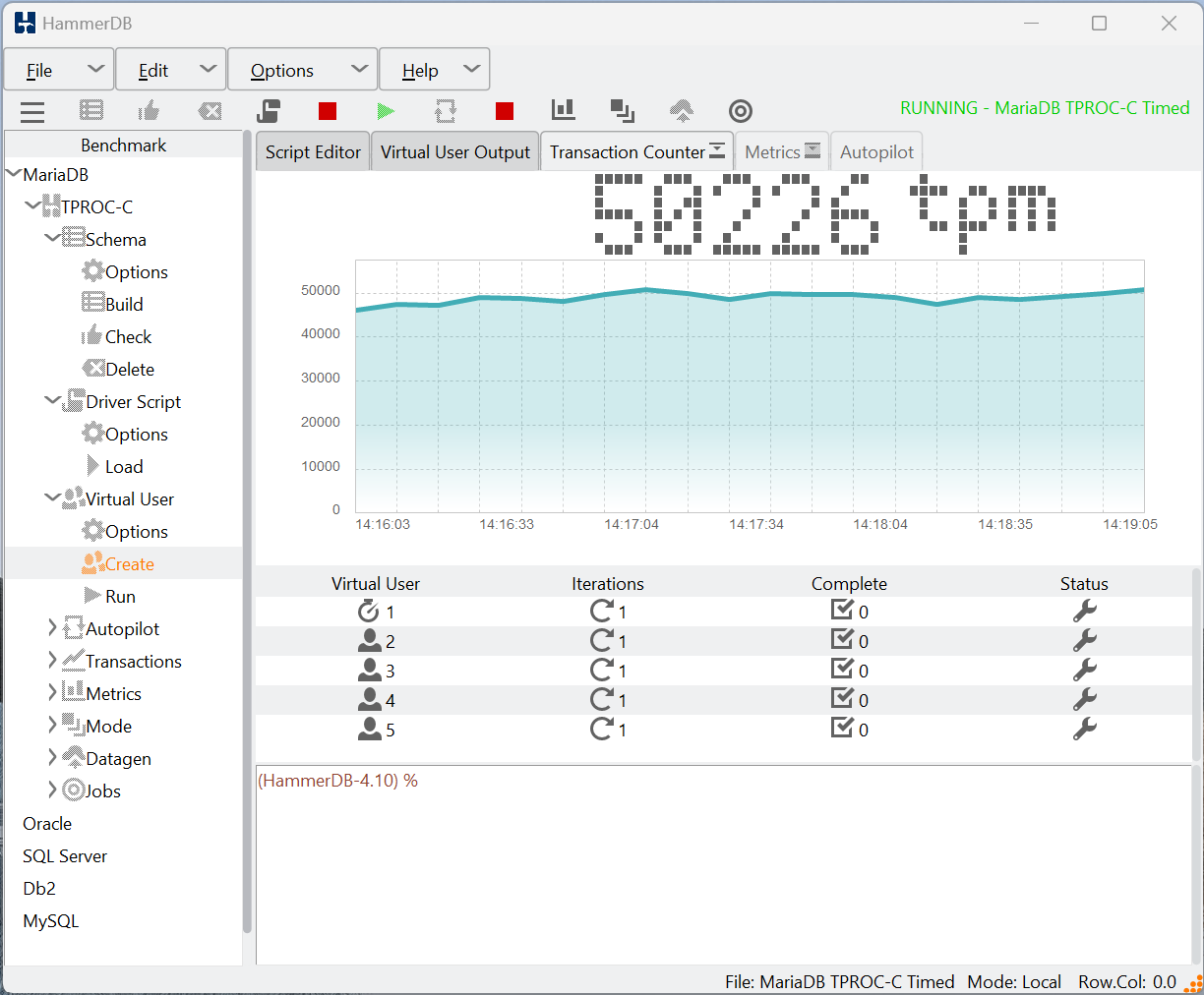
With this setting enabled, run your MariaDB TPROC-C workload as normal.
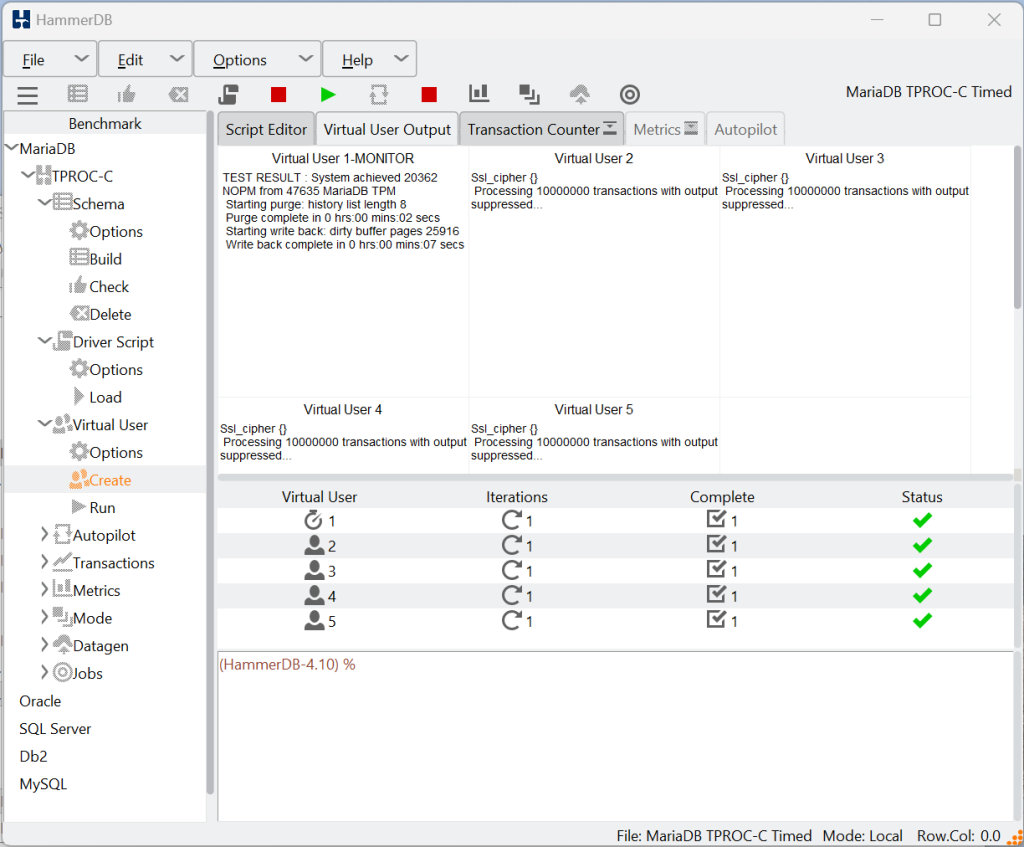
Once the run has completed it will dynamically set the variables to run the purge and write back and restore your variables when complete.
Choosing optimal purge settings
Of course for this notebook based example the history list length does build up unduly over the course of the workload, however in a larger server environment with high transaction rates it is possible to see history list lengths such as follows depending on your purge settings.
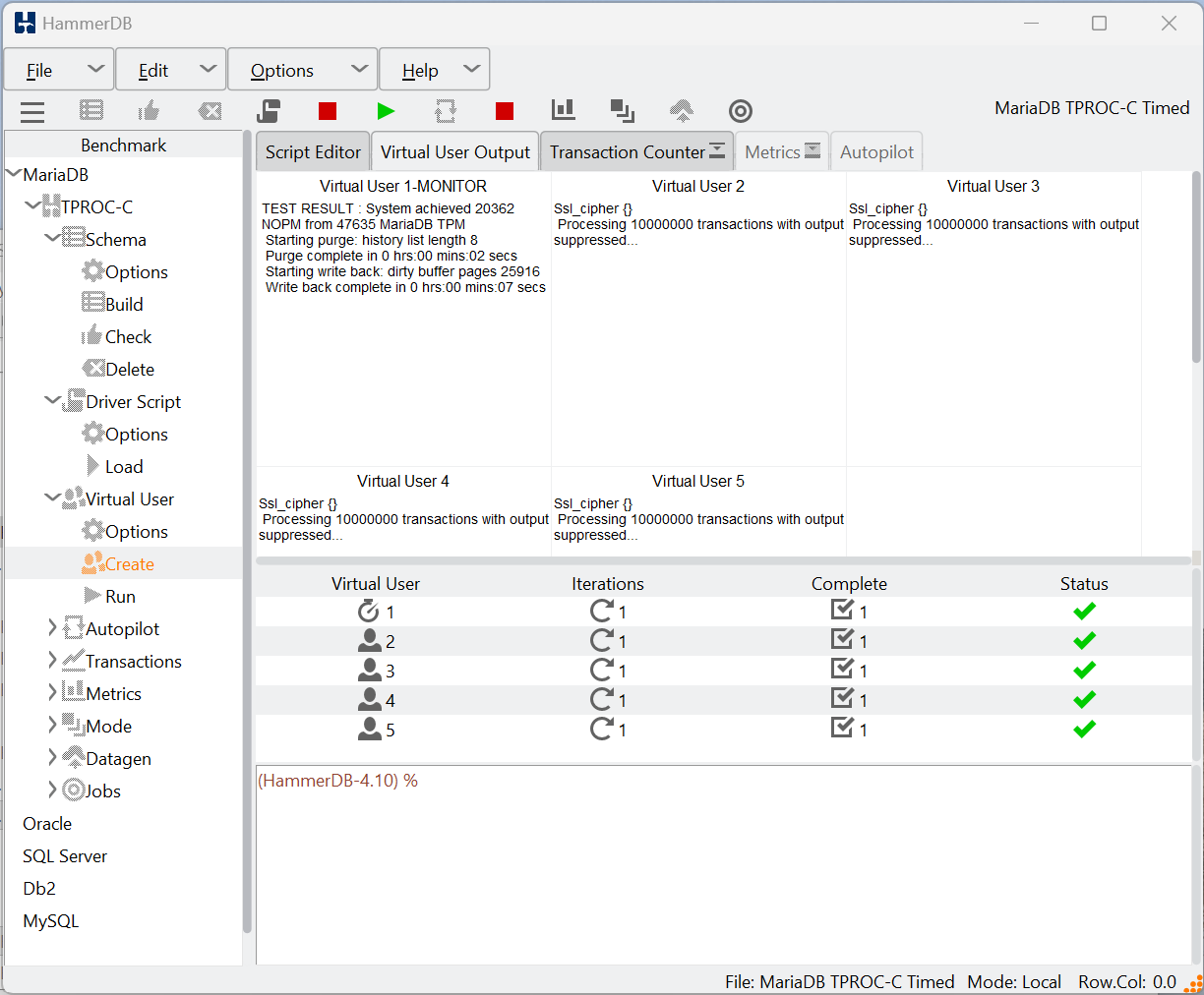
"TEST RESULT : System achieved 916487 NOPM from 2128748 MariaDB TPM",
"Starting purge: history list length 13107078",
"Starting write back: dirty buffer pages 2289677",
Typically for optimal performance during a HammerDB run you want purge_threads and batch_size to be at the default settings as follows innodb_purge_threads =4 , innodb_purge_batch_size = 1000, and then set max_purge_lag and purge lag_delay to low values so we minimize delays during the test, such as innodb_max_purge_lag=0 and innodb_max_purge_lag_delay=1. As described previously, even in this large server environment HammerDB will modify these settings to accelerate the purge and write back after the run has completed and then restore your settings when it has finished ready for the next workload giving us the best possible results each time.
Summary
Now that MariaDB from version 10.7.0 allows us to dynamically set the purge settings we can take advantage of this to complete the purge after a run has completed before the next one starts so that our test runs are entirely repeatable without being impacted by purging.
Thank-you to Marko Mäkelä of MariaDB for guidance on exactly which settings were needed for purge and write back to make this new HammerDB feature possible.