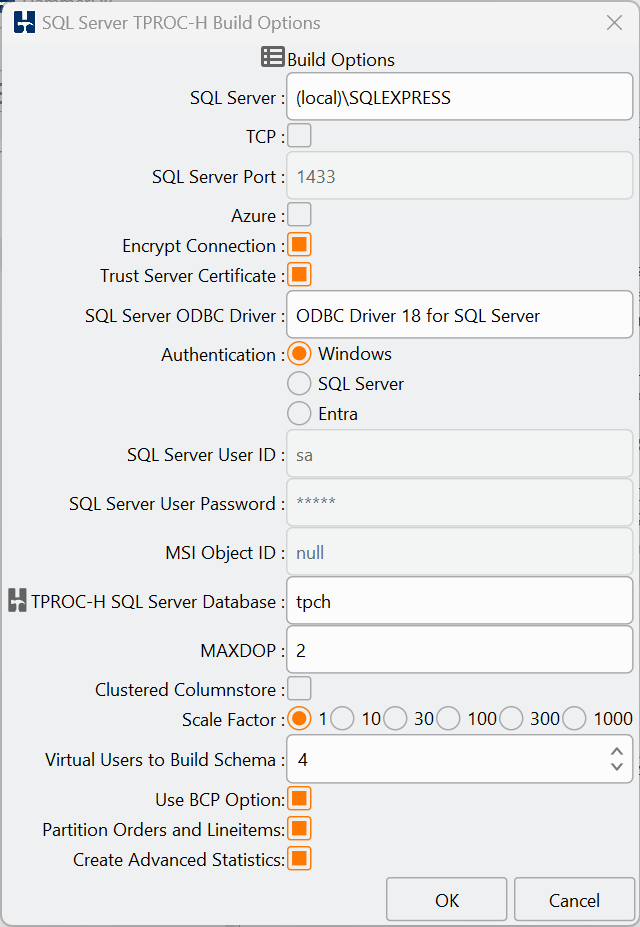
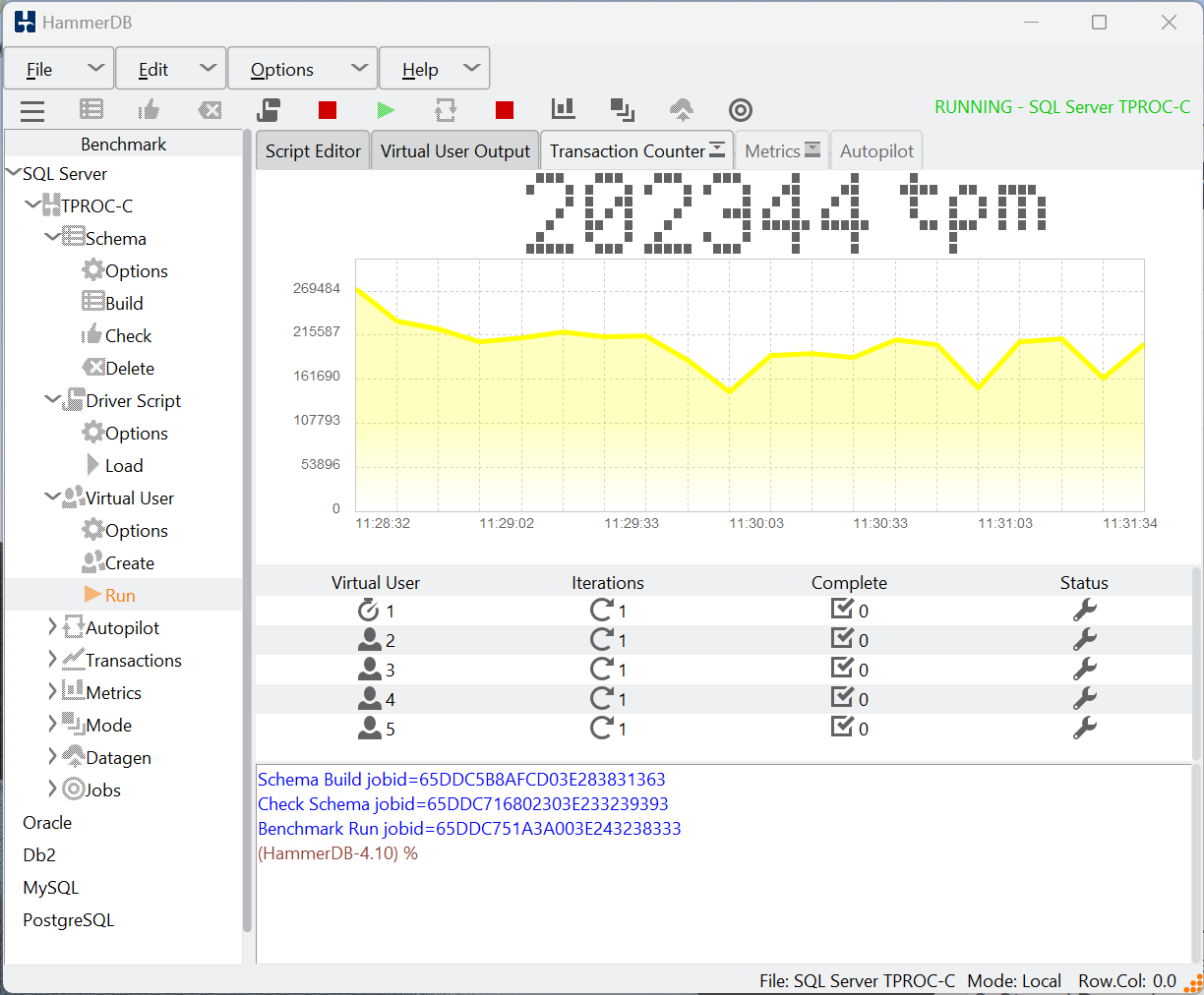
A frequently asked question with HammerDB is when a user is using the TPROC-C workload to test database failure and failover scenarios, by deliberately killing connections or shutting down the database during a workload and then restarting it. This post provides a guide to configuring HammerDB for such a scenario and considerations to be aware of when doing so.
Is a TPROC-C workload valid if you have restarted the database?
This is an important consideration that is often missed, so although it seems obvious, it is worth reiterating that benchmarking applications are not typically designed to be disconnected and the database restarted whilst the workload is running. Of course, you can configure your test environment however you wish, and HammerDB is scripted for exactly this flexibility. However, your results will not be valid or comparable to other results. Additionally, as HammerDB is designed as a benchmarking application, there are no plans to extend functionality to automatically recover in-flight tests from database failures. If the database ‘goes away’ during a test, then the test is invalid and the database should be restarted and the benchmark re-run in its entirety.
Nevertheless, having said this, HammerDB has additional functionality to both make multiple connections to test environments and run test scripts multiple times.
Connect pool functionality for clusters
Firstly, when testing clusters, it is possible to configure a pool of connections for HammerDB to use to connect to multiple instances at the same time. We can also configure multiple databases in the same instance to test at the same time as well. In the example below, we have configured this connect pool for PostgreSQL to connect to 3 different databases and round-robin the connections between all of them. Note that you can direct each stored procedure to a different instance, such as read-write vs read-only.
HammerDB-4.11/config/connectpool$ more pgcpool.xml
<connpool>
<connections>
<c1>
<pg_host>localhost</pg_host>
<pg_port>5432</pg_port>
<pg_sslmode>prefer</pg_sslmode>
<pg_user>tpcc1</pg_user>
<pg_pass>tpcc1</pg_pass>
<pg_dbase>tpcc1</pg_dbase>
</c1>
<c2>
<pg_host>localhost</pg_host>
<pg_port>5432</pg_port>
<pg_sslmode>prefer</pg_sslmode>
<pg_user>tpcc2</pg_user>
<pg_pass>tpcc2</pg_pass>
<pg_dbase>tpcc2</pg_dbase>
</c2>
<c3>
<pg_host>localhost</pg_host>
<pg_port>5432</pg_port>
<pg_sslmode>prefer</pg_sslmode>
<pg_user>tpcc3</pg_user>
<pg_pass>tpcc3</pg_pass>
<pg_dbase>tpcc3</pg_dbase>
</c3>
</connections>
<sprocs>
<neworder>
<connections>c1 c2 c3</connections>
<policy>round_robin</policy>
</neworder>
<payment>
<connections>c1 c2 c3</connections>
<policy>round_robin</policy>
</payment>
<delivery>
<connections>c1 c2 c3</connections>
<policy>round_robin</policy>
</delivery>
<stocklevel>
<connections>c1 c2 c3</connections>
<policy>round_robin</policy>
</stocklevel>
<orderstatus>
<connections>c1 c2 c3</connections>
<policy>round_robin</policy>
</orderstatus>
</sprocs>
</connpool>
To use this XML configuration, select XML Connect Pool in the connection options.
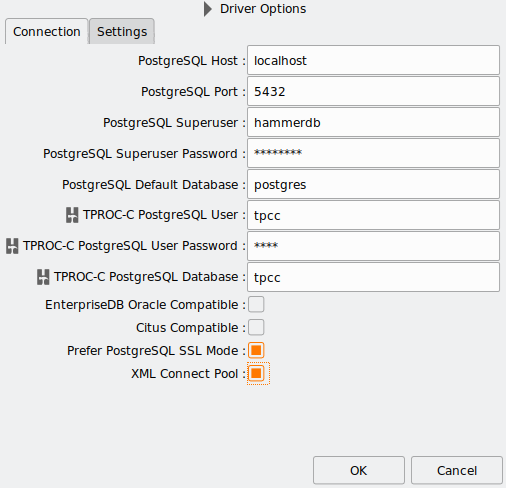
See this post for more details on configuration. When we run the workload, we now make a connection to all the configured databases and run the transactions according to the defined policy.
If we look at the configured connections when the workload has started, we can see the multiple connections across the defined databases. Note in this example the main connection for measuring the NOPM/TPM values connects to the databases tpcc1.
00:00:00 postgres: tpcc1 tpcc1 127.0.0.1(52450) idle
00:00:07 postgres: tpcc1 tpcc1 127.0.0.1(34704) idle
00:00:07 postgres: tpcc2 tpcc2 127.0.0.1(34710) SELECT
00:00:07 postgres: tpcc3 tpcc3 127.0.0.1(34722) idle
00:00:00 postgres: tpcc1 tpcc1 127.0.0.1(34738) idle
00:00:07 postgres: tpcc1 tpcc1 127.0.0.1(34748) idle
00:00:07 postgres: tpcc2 tpcc2 127.0.0.1(34758) idle
00:00:07 postgres: tpcc3 tpcc3 127.0.0.1(34770) SELECT
00:00:00 postgres: tpcc1 tpcc1 127.0.0.1(34786) idle
00:00:07 postgres: tpcc1 tpcc1 127.0.0.1(34788) idle
00:00:07 postgres: tpcc2 tpcc2 127.0.0.1(34792) idle
00:00:07 postgres: tpcc3 tpcc3 127.0.0.1(34804) SELECT
00:00:00 postgres: tpcc1 tpcc1 127.0.0.1(34820) idle
00:00:07 postgres: tpcc1 tpcc1 127.0.0.1(34822) SELECT
00:00:07 postgres: tpcc2 tpcc2 127.0.0.1(34826) idle
00:00:07 postgres: tpcc3 tpcc3 127.0.0.1(34836) idle
00:00:00 postgres: tpcc1 tpcc1 127.0.0.1(34850) idle
When the test has finished, the NOPM/TPM values are reported from the main connection.
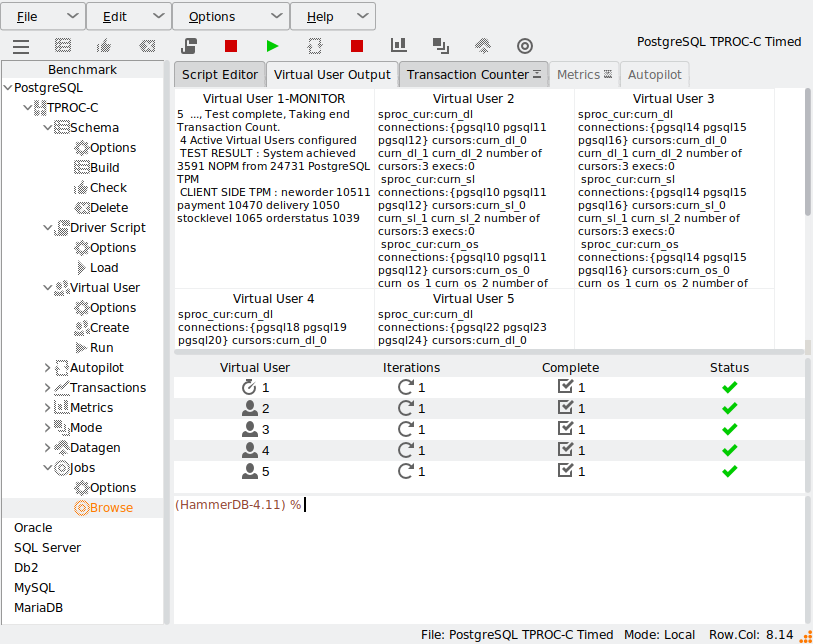
Some databases will report the NOPM from across the cluster but some only per database and therefore this feature will also report the client side TPM to monitor the values per connection.
"4 Active Virtual Users configured",
"1",
"TEST RESULT : System achieved 3591 NOPM from 24731 PostgreSQL TPM",
"2",
"VU2 processed neworder 18343 payment 18127 delivery 1823 stocklevel 1853 orderstatus 1838 transactions",
"0",
"Vuser 2:FINISHED SUCCESS",
"4",
"VU4 processed neworder 18178 payment 18294 delivery 1791 stocklevel 1861 orderstatus 1860 transactions",
"0",
"Vuser 4:FINISHED SUCCESS",
"5",
"VU5 processed neworder 18269 payment 18206 delivery 1824 stocklevel 1866 orderstatus 1819 transactions",
"0",
"Vuser 5:FINISHED SUCCESS",
"3",
"VU3 processed neworder 18789 payment 18668 delivery 1912 stocklevel 1878 orderstatus 1761 transactions",
"0",
"Vuser 3:FINISHED SUCCESS",
"1",
"CLIENT SIDE TPM : neworder 10511 payment 10470 delivery 1050 stocklevel 1065 orderstatus 1039",
"0",
"Vuser 1:FINISHED SUCCESS",
"0",
"ALL VIRTUAL USERS COMPLETE"
When testing clusters, this feature allows you to measure the throughput across multiple instances at the same time and therefore also test the planned failure of some of the databases you are testing.
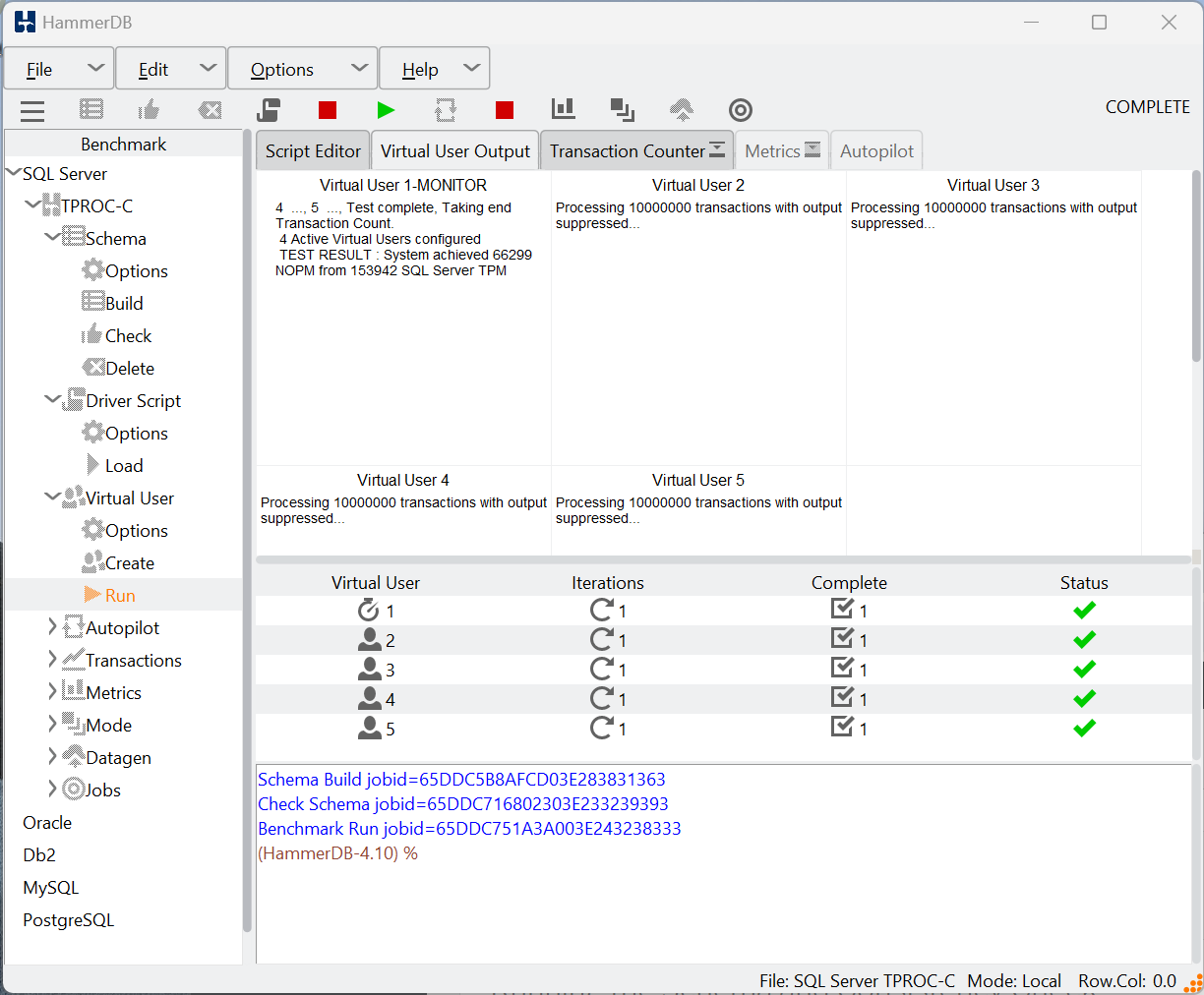
Virtual User Iterations
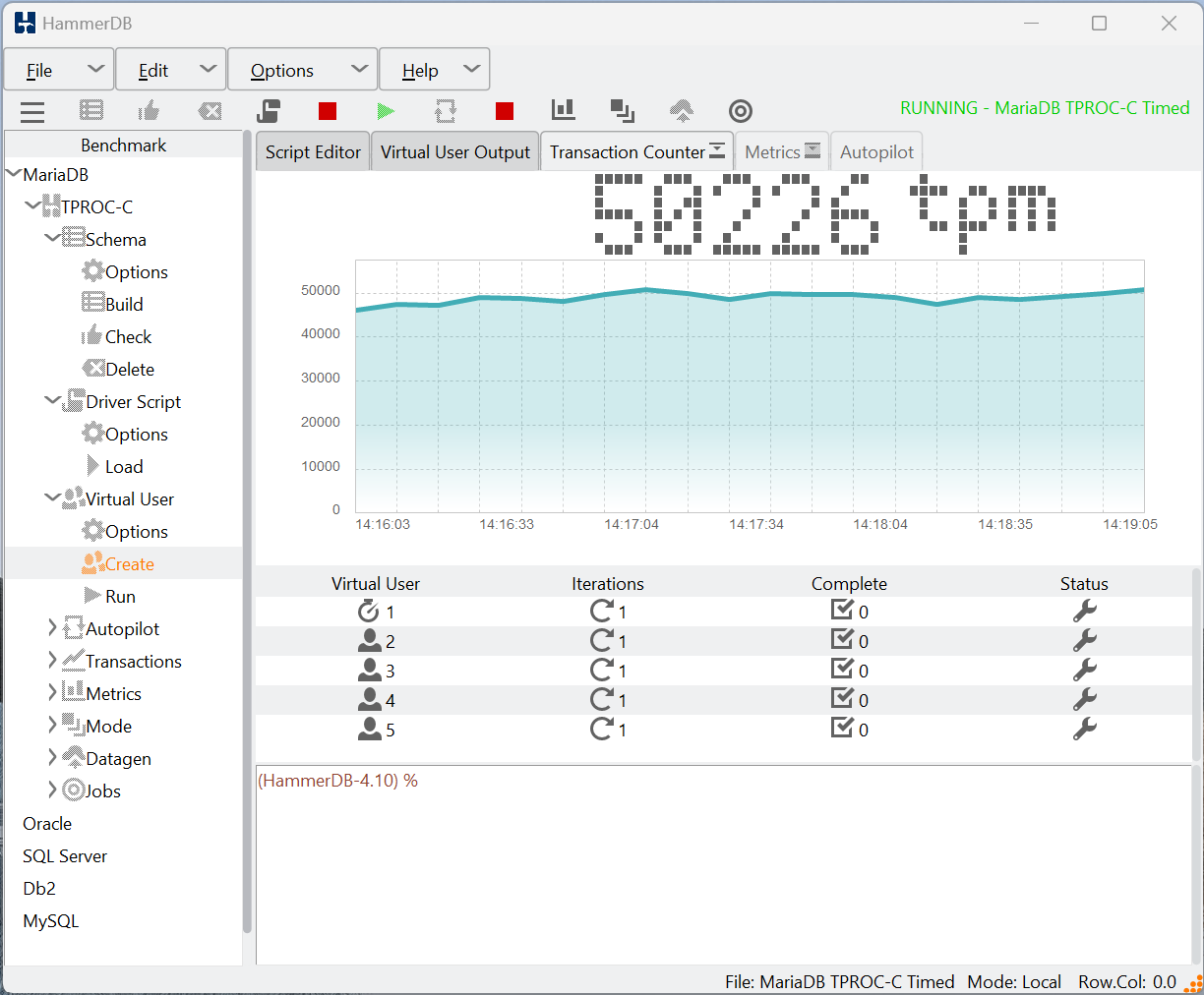
If you want to test killing connections and have HammerDB reconnect, then you should use the Virtual User Iterations feature. You can think of this value as an outer loop around Total Transactions per User set in the Driver Options for a workload. For example, if you change Total Transactions per User to 100,000 and Virtual User Iterations to 10 then each Virtual User will do 1000,000 transactions in total across 10 separate sessions having logged off and on 10 times. Of course, however, if you kill the connection first then the session will also reconnect, allowing you to do the same for failure scenarios.
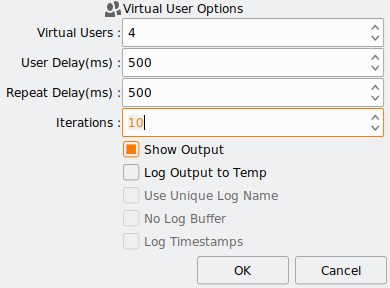
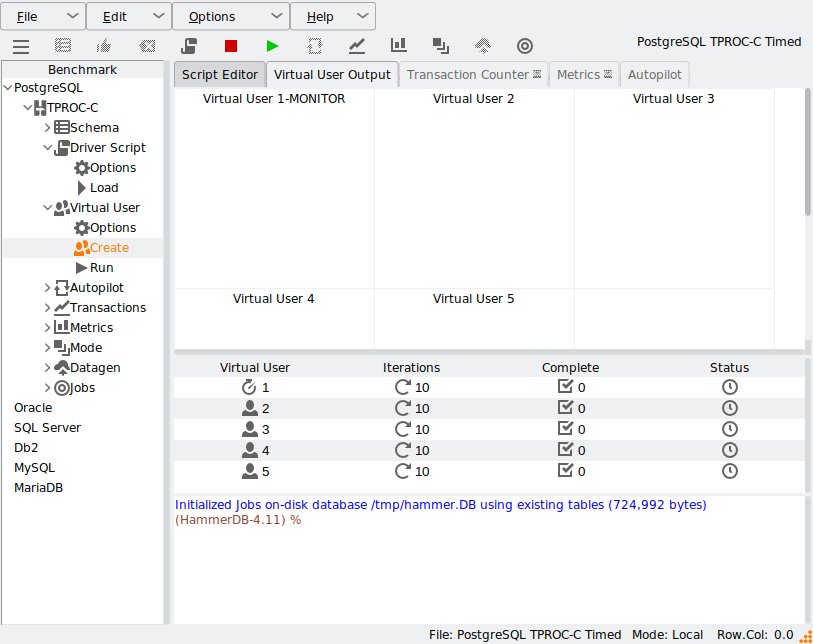
When you create the virtual users, you can see the iterations value in the central panel.
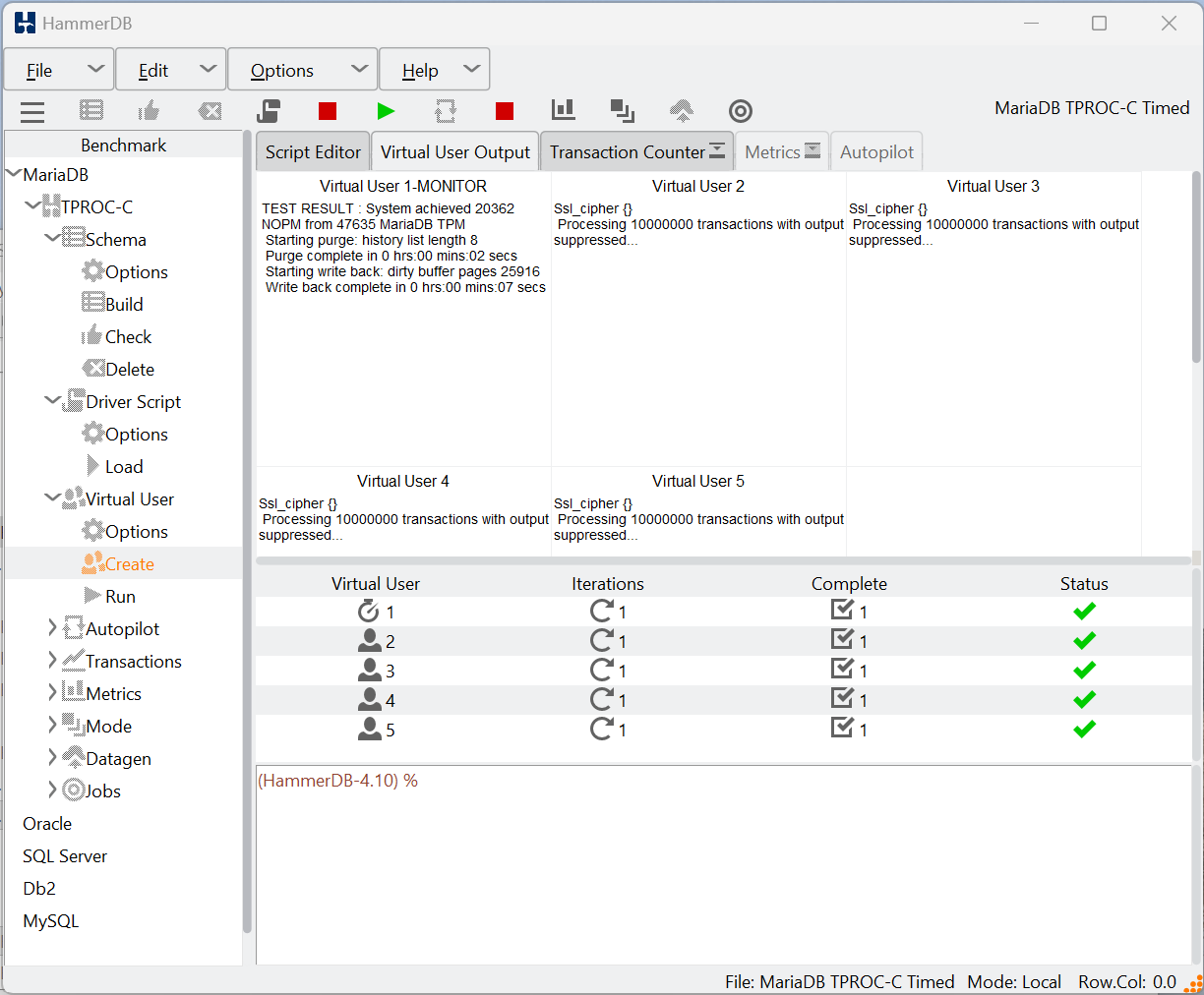
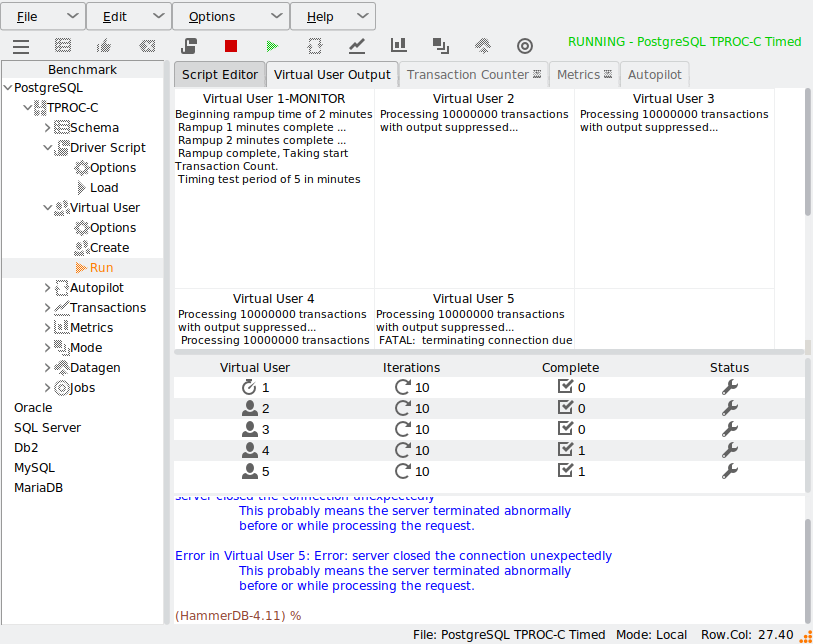
Now if you terminate a session, in this example with select pg_terminate_backend(9011); where 9011 is a Virtual User pid. You can see the error, and that the Virtual User has reconnected.
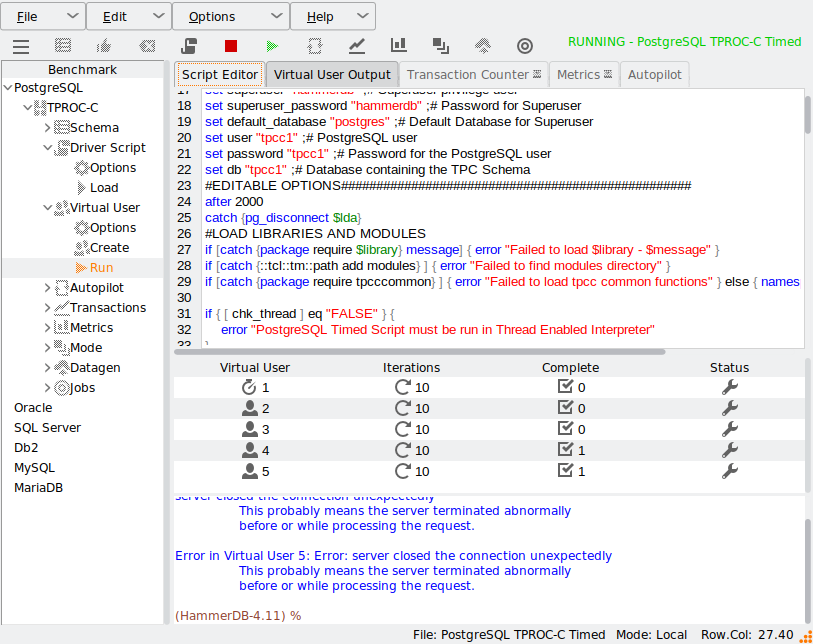
Also note that when killing connections, they can be left in an uncertain state that can result in crashes or errors when the same thread starts running again. Therefore, it is best practice to add a short pause before reconnecting, as shown with the line “after 2000” below and also to preemptively close the connection before trying to reconnect, in this example with catch {pg_disconnect $lda}
Summary
Benchmarking applications are not typically designed for failure and failover scenarios. Nevertheless, HammerDB provides users with the functionality to create their own bespoke test environments that allow them to test multiple instances in a cluster and also to reconnect and restart a test after a failure. Using both features either independently or combined enables having an application that can test database or connection failure instead of benchmarking performance.