One of the key differences that stands out with HammerDB v4.0 compared to previous releases is that the workload names have changed from TPC-C and TPC-H to TPROC-C and TPROC-H respectively and therefore a key question is how are the v4.0 workloads different from the previous releases of v3.3 and earlier, what has changed and how does this impact interpreting results? The simple answer is nothing, the workloads are exactly the same workloads derived from the TPC-C and TPC-H specifications and HammerDB v4.0 can be seen as a continuation and enhancement from previous releases, only the name has changed, not the workload itself. From an engineering perspective this may be all that you need to know. However a reasonable follow-on question is then why change the name at all? This post aims to give some of the background to the change and provide you with the information of where and how the TPROC-C and TPROC-H differ from a ‘real’ TPC-C and TPC-H respectively.
First of all it has always been clear in the HammerDB documentation that the TPROC-C/TPC-C and TPROC-H/TPC-H workloads have not been ‘real’ audited and published TPC results instead providing a tool to run workloads based on these specifications. For example HammerDB has not used tpmC terminology to report TPC-C based metrics instead using TPM and NOPM nomenclature. Initially from TPC documentation it was not specified whether using TPC-C and TPC-H terminology for derived workloads was permitted. Additionally both commercial and open source tools based on the specifications also continued to use TPC-C and TPC-H to describe these workloads. This has now been made explicitly clear, using TPC-C or TPC-H for a non-compliant workload to the full specification is a trademark violation. For this reason HammerDB has changed the workload names to be legally compliant. Any tools using TPC-C, TPC-H (or other trademarked TPC workload names) for tools or workloads both commercial and open source should also consider renaming for trademark compliance purposes or take legal guidance.
But why is this important? Surely it was clear that as a derived workload HammerDB results were not actual fully audited TPC results so that this non-compliance was implicit? In the vast majority of cases this was the case and even when using TPC terminology it was clear that using for example TPC-C meant “derived from TPC-C”. However there were cases where intermediate understanding based on some familiarity with the specifications (but without the implicit understanding that the difference was already clear) have questioned the validity of published performance data by users based on this implicit understanding. This change makes that difference explicit and puts everyone on the same page, TPROC-C means derived from TPC-C.
So why derive a workload from TPC-C or TPC-H at all and instead just rely on vendor published and fully audited results? This question is the very essence of what HammerDB is, a tool that takes the well designed and scalable TPC-C and TPC-H specifications and implements a workload derived from them that is accurate and repeatable yet tests database capabilities to the full (compared to alternative simple 1-table no contention workloads) so that running database performance benchmarks becomes fast, low cost and accessible to all, making database benchmarks open source thereby allowing anyone to compare the performance of their databases.
A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint. In the days before highly performant SSDs and persistent memory, database benchmarks had a significant challenge in comparing performance due to the available I/O performance. For TPC-C this meant enough available spindles to reduce I/O latency and for TPC-H enough bandwidth for data throughput. Fully audited configurations would require multiple racks of I/O capacity to reach maximum CPU performance. This was both expensive and time consuming to configure. Even with superior I/O performance today the I/O configuration required on-premise or in the cloud remains costly.
Additionally a fully audited benchmark requires multiple client servers to sustain the large volume of clients as well as a TP Monitor (Transaction Processing Monitor) This TP monitor acts as middleware transferring the transactions between the clients and the database server. The challenge was how to take the essence of the TPC specifications that are made available for free and implement the workloads in a method that maximises CPU performance and can be run on anything from laptops to servers without the significant expense of I/O capacity and multiple client servers to run the workloads. Therefore for HammerDB TPROC-C we eliminated keying and thinking time and eliminated the requirement for terminals. This meant we could dispense with the TP-monitor, reduce the number of clients, reduce the storage and the schema size but still run similar transactions to the TPC-C specification so that it was running a scalable and repeatable workload in a CPU and memory intensive manner.
Over time since we first ran HammerDB workloads we noticed that the CPU generation to generation performance ratios between systems was the same with this CPU intensive default mode as the official published TPC-C benchmarks. I.e. if system A generated 1.5X more transactions than system B in the fully audited benchmark then the HammerDB result was also 1.5X better. Consequently we were getting very similar insights both faster and cheaper meaning we could test orders of magnitude more configurations in the same amount of time generating relative performance ratios.
Why would this be the case? Surely if the database schema is smaller, the workload more intensive, and there is not the same I/O capacity demands then the results would be different. The key aspect is the presence of the TP Monitor and this is arguably the area where the most confusion arose in stating that a HammerDB TPC-C workload was not an actual TPC-C workload which should have already been clear. Typically in a fully audited TPC-C the client sessions are not connecting directly to the database with many 1000’s of sessions. Instead all of the client servers are connecting to the TP monitor. This is not a new concept, as given in the description for the earlier TPC-B workload “a transaction monitor can multiplex transaction streams to match the processing profile of the database subsystem. For example, 1000 user terminals would present transactions with human think times and delays, and the transaction monitor will concentrate them down to a steady stream of, say, 50 concurrent processes.” Therefore the actual database server workload is both CPU and memory intensive with actual connections typically numbered in the hundreds processing transactions for the clients managed by the TP monitor. HammerDB eliminates this stage instead implementing a workload that connects the steady stream of transactions directly to the database. Additionally because the number of Virtual Users is lower for the HammerDB default mode (see below for alternatives) each Virtual User will choose a home warehouse at random. Once that home warehouse is chosen then most of the work takes place against that warehouse – therefore for example you hit max CPU at 200 VUsers then most of the work is on 200 warehouses regardless of how many you have created. As the home warehouse is chosen at random however you want enough to ensure an even spread of Virtual Users across the warehouses. Therefore the general advice is 250-500 warehouse per socket and for example a starting point of 1000 warehouses for a 2 socket server regardless of the database is a good starting point. This is also the reason why the default maximum number of warehouses is 5000. You can change this if you wish, however this limit is set to prevent a typical error of over configuring the database size in the expectation that it will improve performance.
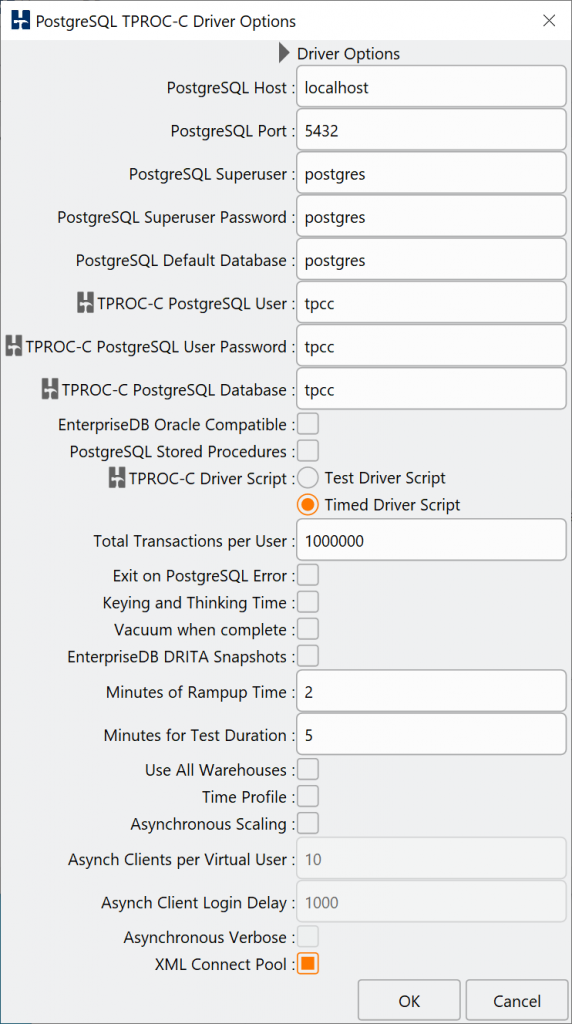
Nevertheless more recently SSDs and persistent memory are lowering the price points for high performance I/O increasing the desire to test more I/O that wasn’t there when people needed to buy a dedicated storage array to do so. For this reason beyond the default mode there are the 3 more advanced features:
- Use All Warehouses (Choose a new warehouse per transaction)
- Event driven scaling (asynchronous clients with keying and thinking time)
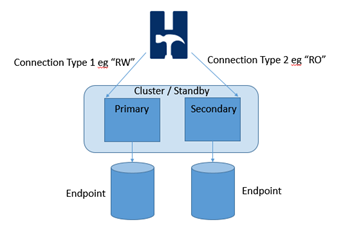
- XML Connect Pooling (test distributed clusters)
These can be used separately or together for the sort of scenarios where it is desired to increase the I/O load, the number of Virtual Users or to test a distributed environment. However to test a large number of Virtual Users with event driven scaling will need increasing the number of HammerDB clients with primary and replica modes and you will also need to implement a form of middleware to concentrate these connections. Therefore you are moving away from a more agile and rapid form of testing to more complex configurations. You are entirely in control of your test environment and therefore the choice is yours dependent on the scenarios you wish to test rather than being bound by a more rigid specification.
In terms of analytics and the TPROC-H workload derived from TPC-H, this specification does not require middleware so when running TPROC-H you are close to the specification, however there remain differences. For example the TPC-H specification includes measuring database load times that is beyond the scope of HammerDB and you may wish to implement features such as in-memory column stores, partitioning and compression to improve performance. HammerDB cannot implement advanced features that may not be available in all test environments and therefore builds a base configuration that would be available to all. The user can then modify the schema as they wish. For this reason TPROC-H is also a workload derived from TPC-H and has moved away from providing information on calculating the QphH figure to focusing on actual query times for power and throughput tests and a total geometric mean of query times.
In conclusion, TPROC-C and TPROC-H are the new names for the same HammerDB specific workloads that mean “derived from TPC-C” and “derived from TPC-H” respectively to make running workloads based on these specification both faster and cheaper and available to all. Official TPC-C and TPC-H compliant results can as has always been the case only be found on the official TPC website.