
Prior to version 4.2 the limits to the size of the schema that could be generated was set to 5000 warehouses in the GUI and 30,000 if using the datagen feature to generate flat files for external loading. From version 4.2 these limits have been increased to 100,000 for both features. This post gives a background to the schema size limits, guidance on the warehouse count and expected size limits. It also shows how to manually exceed the 100,000 limit if you wish.
Up to version 4.1 when using the GUI the number of warehouses is adjusted by a spinbox with an upper limit set to 5000. You could manually enter a figure larger, but would then receive the error shown that 5000 was the limit.
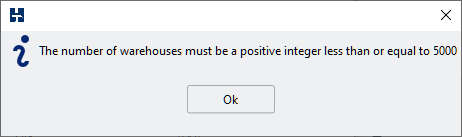
This was often interpreted as a limit of the amount of data that HammerDB could generate. Instead, however, this was an imposed limit to encourage right-sizing of the test database instead of over-sizing.
The number of warehouses is passed as one of the parameters in the last line of the build script that has no limit. In the example below, the value 5000 can be seen as the fourth argument to the function do_tpcc. If you stop the build, manually modify this value and re-run the build, it will generate the number of warehouses you have defined. This is the same for the previous 5000 limit or the current 100,000 limit.
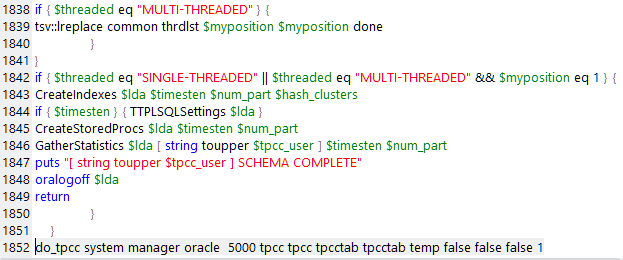 However, the precision of some numeric data types may not have been sufficient for larger values in some databases. For example, for Oracle as shown “W_ID” of the table WAREHOUSE was set to the NUMBER data type with scale and precision of (4,0) meaning that the maximum number of warehouses permitted was 9999 before Oracle would generate an error.
However, the precision of some numeric data types may not have been sufficient for larger values in some databases. For example, for Oracle as shown “W_ID” of the table WAREHOUSE was set to the NUMBER data type with scale and precision of (4,0) meaning that the maximum number of warehouses permitted was 9999 before Oracle would generate an error.
"CREATE TABLE WAREHOUSE (W_ID NUMBER(4, 0), W_YTD NUMBER(12, 2), W_TAX NUMBER(4, 4), W_NAME VARCHAR2(10), W_STREET_1 VARCHAR2(20), W_STREET_2 VARCHAR2(20), W_CITY VARCHAR2(20), W_STATE CHAR(2), W_ZIP CHAR(9)) INITRANS 4 PCTFREE 99 PCTUSED 1"
All databases have been checked and updated for v4.2 to ensure that schema builds of up to 100,000 warehouses will complete without error.
Regarding the amount of disk space that should be reserved for a schema build, the general guidance is to allow up to 100MB per warehouse. Typically, not all of this space will be needed and varies per database, however it should not exceed this value. Therefore, for 100,000 warehouses, 10TB of space should be allowed.
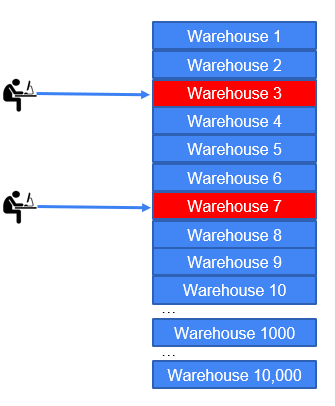
However, be aware that just because you can build schemas of up to 100,000 warehouses, it does not necessarily mean that this will right for you. With the default workload, each Virtual User will process 90% of its transactions against its home warehouse selected at random at the start of the test. Consequently, as shown if you are running 2 Virtual Users it makes little difference if you have created, 10, 1000, 10,000 or 100,000 warehouses, aside from the 2 selected at random most of that data will remain idle and will not affect the result of the test. You should create a schema large enough to allow an even, uncontended, random distribution of Virtual Users for the maximum Virtual User count you will expect to create.
For further information on right sizing, see the post:
Where larger warehouse counts are of most benefit is when using advanced driver script options such as use all warehouses and event driven scaling. These are areas where creating larger schema sizes can add additional benefit and insight to your testing above and beyond the default schema installations.