
HammerDB is a load testing and benchmarking application for relational databases. All the databases that HammerDB tests implement a form of MVCC (multi-version concurrency control). This helps to minimise locking allowing multiple sessions to access the same data at the same time. On high-performance multi-core systems all the supported databases can return performance in the many millions of transactions per minute. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. This is why the choice of programming language is so important from the outset.
This post explains why HammerDB made the language decisions it made to make it the best performing and most usable database benchmarking software.
Basic Benchmarking Concepts
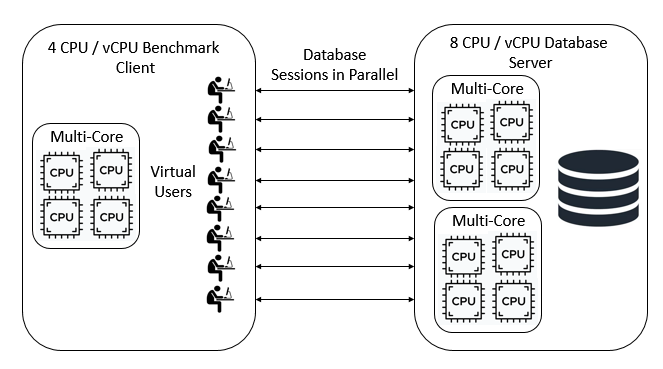
As we have seen databases are designed to handle multiple database sessions at the same time. To benchmark a database we introduce the concept of a Virtual User. The benchmarking software simulates the actions of multiple individual users and these users must run in parallel to test the MVCC (Multiversion Concurrency Control) capabilities of the database. There is a key distinction here between parallelism and concurrency. It is important that the concurrency between sessions is handled at the database not at the client because that is how databases are accessed in the real world. When we have multiple CPU cores on both the benchmark client and database server it is crucial that these database sessions run independently of each other at the same time, in parallel. For simplicity, we do not include networking or transaction management middleware in this discussion because although important in the real world they do not affect the key concepts.
SQL
Firstly, for a database benchmarking application it should not come as a huge surprise that the key language used for testing databases is Structured Query Language known as SQL. For HammerDB both TPROC-C and TPROC-H run all of their workloads on the database being tested in SQL. The following is an example from TPROC-C from SQL Server.
SELECT @st_o_id = district.d_next_o_id FROM dbo.district WHERE district.d_w_id = @st_w_id AND district.d_id = @st_d_id SELECT @stock_count = count_big(DISTINCT stock.s_i_id) FROM dbo.order_line , dbo.stock WHERE order_line.ol_w_id = @st_w_id AND order_line.ol_d_id = @st_d_id AND (order_line.ol_o_id < @st_o_id) AND order_line.ol_o_id >= (@st_o_id - 20) AND stock.s_w_id = @st_w_id AND stock.s_i_id = order_line.ol_i_id AND stock.s_quantity < @threshold OPTION (LOOP JOIN, MAXDOP 1)
and the following from TPROC-H
select top 100 s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_address, s_phone, s_comment from part, supplier, partsupp, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and p_size = 47 and p_type like '%COPPER' and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'EUROPE' and ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'EUROPE' ) order by s_acctbal desc, n_name, s_name, p_partkey option (maxdop 2)
Application Logic in Stored Procedures
So the interaction with the database is in SQL. For the TPROC-H workload this is all we need the queries are long-running analytics queries so once executed on the database do not need to wait for the benchmarking client. TPROC-C however is derived from the TPC-C specification and requires application logic around the SQL. HammerDB implements the TPROC-C application logic in the form of stored procedures for all the supported databases.
| Database | Application Logic |
| Oracle | PL/SQL |
| SQL Server | T-SQL |
| Db2 | SQL PL |
| PostgreSQL | PL/pgSQL |
| MySQL | stored program language |
So now our TPROC-C example from the Stock Level stored procedure on SQL Server begins as follows.
CREATE PROCEDURE [dbo].[slev] @st_w_id int, @st_d_id int, @threshold int AS BEGIN DECLARE @st_o_id int, @stock_count int BEGIN TRANSACTION BEGIN TRY SELECT @st_o_id = district.d_next_o_id FROM dbo.district WHERE district.d_w_id = @st_w_id AND district.d_id = @st_d_id ....
Why does it matter that we implement the application logic in the form of stored procedures? To prevent the roundtrip between the client and database becoming the bottleneck. As an illustration if we compare HammerDB with a sysbench workload both running on the same system and same MySQL database we can observe that both workloads are driving 75-80% of the CPU on database throughput however sysbench is utilising 20% system time compared to 3% for HammerDB. (The HammerDB workload shows that database locking prevents full CPU utilisation on the MySQL server).
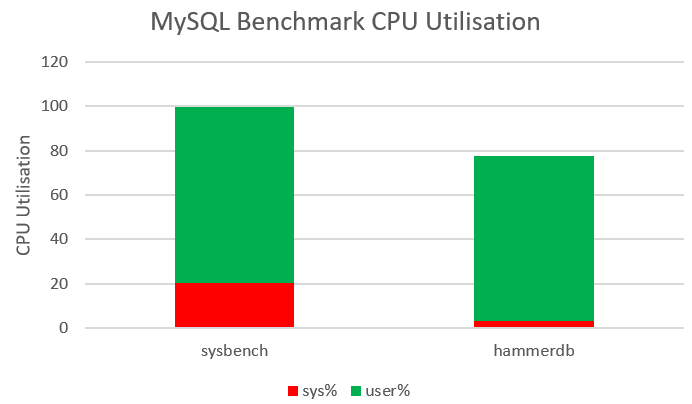
Why is this happening? sysbench has the application logic in the client and is therefore spending 6-7X of the time on socket communication because every single SQL statement requires a separate round trip to the client (recvfrom and sendto).
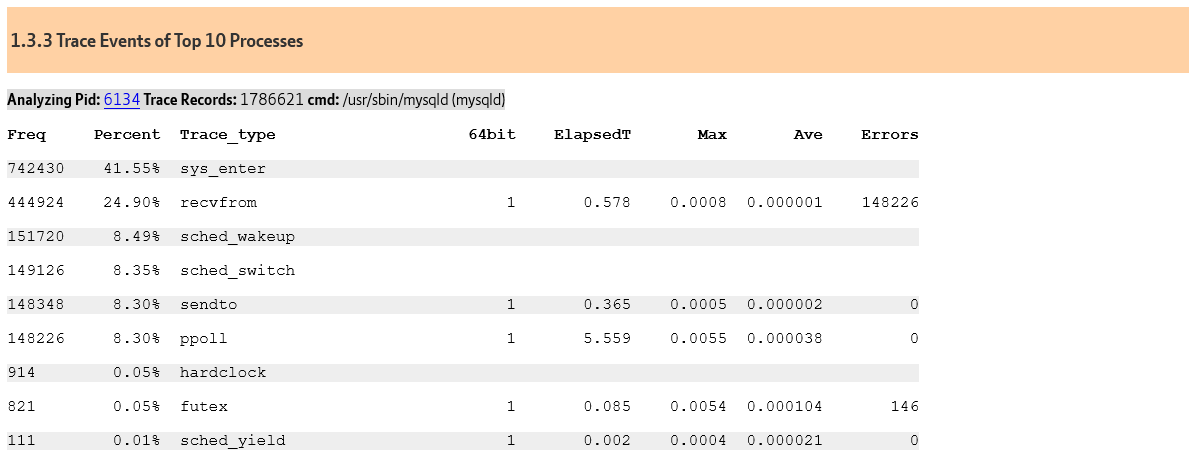
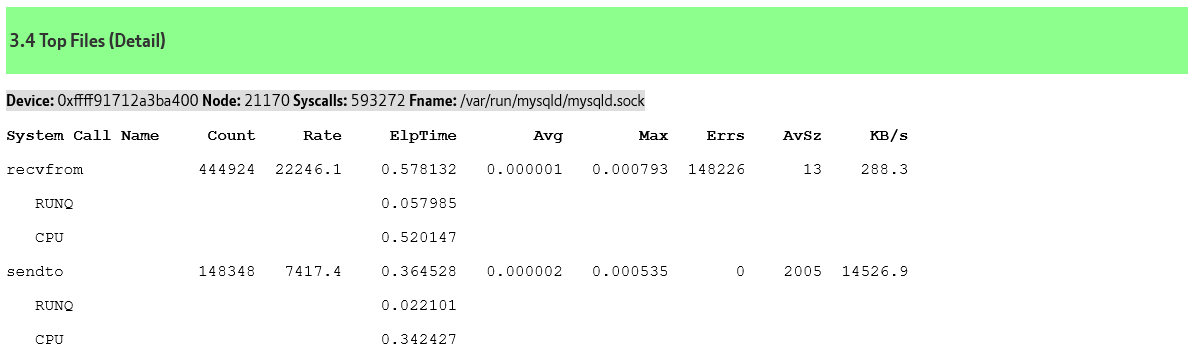
However, having the application logic in the client is even worse because you are sacrificing key database efficiencies of prepared statements. Of course, you can prepare individual statements, however you can see major efficiency gains by using natively compiled stored procedures. With HammerDB the stored procedures are compiled (where supported by the database) at the time of schema creation by the HammerDB build. When the HammerDB driver is run we parse the statement to call the procedure once (and only once) per session. The example below is for the NEW ORDER stored procedure for the Oracle database.
"BEGIN neword(:no_w_id,:no_max_w_id,:no_d_id,:no_c_id,:no_o_ol_cnt,:no_c_discount,:no_c_last,:no_c_credit,:no_d_tax,:no_w_tax,:no_d_next_o_id,TO_DATE(:timestamp,'YYYYMMDDHH24MISS')); END;"
We therefore don’t use CPU repeatedly parsing any of the SQL used for the workload. Instead, we are using bind variables and each time we call the stored procedure we bind the INPUT variables, execute the stored procedure and fetch the OUTPUT variables. The driver only needs to generate strings that correspond to the bind variables and therefore not only is it doing much more work per roundtrip it is sending and fetching a lot less data as well.
Database interfaces in C
So our application logic is in SQL and stored procedures and we are preparing once then binding and executing statements multiple times. So lets take a look at an extract of how this is done in HammerDB for Db2 and the language used.
int Db2_bind_exec (ClientData cData, Tcl_Interp * interp, int argc,
CONST84 char *argv[])
{
int i = 1;
Tcl_Channel conn_channel;
Db2Connection *conn;
char id[MAX_ID_LENGTH + 1];
char buff[MAX_ID_LENGTH + 1];
SQLHANDLE hdbc, hstmt;
SQLLEN ival = SQL_NULL_DATA;
short num_params;
int nparam;
char **paramList;
...
conn->rc = SQLFreeStmt(hstmt, SQL_RESET_PARAMS);
if (conn->rc != SQL_SUCCESS)
{
SQLError (henv, conn->hdbc, hstmt,
(SQLCHAR *) & conn->sql_state,
&conn->native_error,
(SQLCHAR *) & conn->error_msg,
sizeof (conn->error_msg), &conn->size_error_msg);
Tcl_AppendResult (interp, conn->error_msg, (char *)NULL);
if (paramList) ckfree((char *) paramList);
return TCL_ERROR;
}
for (i = 0; i < nparam; i++)
{
if (strncmp (paramList[i], "NULL", 4) == 0)
{
/* null bind / conn->rc = SQLBindParameter (hstmt, i + 1, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, 0, 0, NULL, 0, &ival);
}
else
{ / bind value */
conn->rc = SQLBindParameter (hstmt, i + 1, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, 0, 0, paramList[i], 0, NULL);
}
if (conn->rc != SQL_SUCCESS)
{
SQLError (henv, conn->hdbc, hstmt,
(SQLCHAR *) & conn->sql_state,
&conn->native_error,
(SQLCHAR *) & conn->error_msg,
sizeof (conn->error_msg), &conn->size_error_msg);
Tcl_AppendResult (interp, conn->error_msg, (char *)NULL);
if (paramList) ckfree((char *) paramList);
return TCL_ERROR;
}
}
conn->rc = SQLExecute (hstmt);
...If this looks like a lot like the C programming language, that is because it is or to be more precise it is a C program using the Db2 Call Level Interface (CLI) that is the ‘C’ ‘C++’ programming interface for Db2 ‘to pass dynamic SQL statements as function arguments’ which is exactly what we want to do. For all the databases supported we are using a compiled C interface on the client to use the lowest level of most efficient form of access possible.
| Database | Programming Interface |
| Oracle | OCI |
| SQL Server | ODBC |
| Db2 | CLI |
| PostgreSQL | Libpq |
| MySQL | MySQL Native Driver |
Glue language
So now we have all of our application logic in SQL and stored procedures, natively compiled that we can bind and execute. We also have our low-level C level interfaces that can run both SQL and stored procedures at high performance. The next thing we need is what is known as a Glue language. One that can stick all the components together in an application that we can use to run databases benchmarks.
Why not Python as a Glue Language
Surely we can just use any language that we are familiar with? Unfortunately it is not quite this simple. Let’s take a look at using Python as a language to build a driver for a workload derived from TPC-C. There are different language implementations of Python, as we have seen for our high performance benchmarking application our interfaces are written in C so CPython is our only choice. So lets take a look at how this would work in practice.
Referring back to our benchmarking basics we want to run database sessions in parallel. For this reason we need to implement our database sessions in the form of operating system threads. We could use processes, however given we may want to create hundreds or thousands of virtual users multithreading is the best approach to implement a Virtual User.
This is where we hit a roadblock with using Python as a glue language for a benchmarking application, the Python GIL. The GIL or Global Interpreter Lock is a mutex that stops multiple Python threads executing Python bytecodes at the same time.
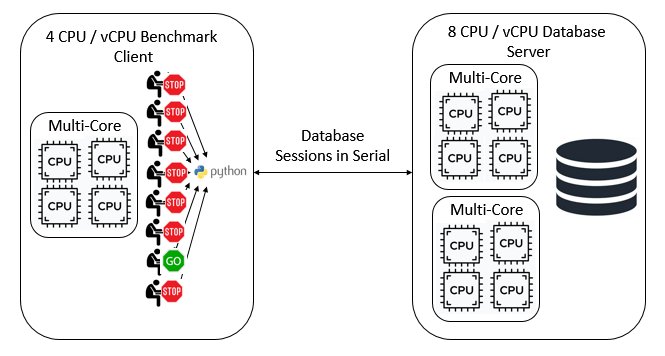
In other words our Virtual Users instead of executing in parallel are now effectively running their database sessions in serial and the more sessions we have the more performance will degrade as each session tries to acquire the GIL. As it says on the Python Wiki ‘it is only in multithreaded programs that spend a lot of time inside the GIL, interpreting CPython bytecode, that the GIL becomes a bottleneck.’ – this describes exactly the scenario that we use for database benchmarking and is discussed further in the section Bytecode Execution.
So having an application client mutex lock that artificially stalls our Virtual Users does not sound good. Unfortunately, however our glue language doesn’t know that we are testing a high performance database processing numerous databases sessions concurrently. Our sessions will also be taking out locks on the database itself meaning that blocked Virtual Users on the client could themselves be blocking running Virtual Users on the database. Conversely, if throughput is limited we could also be preventing the database from handling the database locking that results from running multiple sessions accessing the same data at the same time. In either scenario we are preventing the database from managing sessions concurrently when this is precisely the scenario we want to test.
Why Tcl as a Glue Language
HammerDB abandoned Python as a glue language at the design stage because of the lack of multithreading and parallel capabilities. The only language that met such specific requirements for high throughput database benchmarking was Tcl or Tool Command Language. Not only was it designed from the ground up to interface with applications built in C, but it also supports true multithreading enabling our Virtual Users to be implemented as an independent operating system thread and genuinely run in parallel.
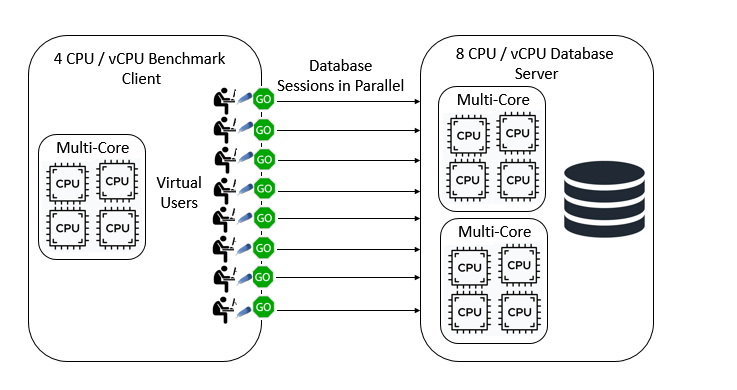
How does Tcl do this if Python can’t? Whereas within Python all threads run in a single interpreter (after acquiring the GIL) in Tcl each thread has its own copy of the interpreter. This is possible because the Tcl interpreter is exceptionally compact and lightweight (Also for this reason Tcl is often used as an embedded language in hardware such as Cisco Routers). By default, there is no shared data between threads, instead each thread runs an event loop completely independently and communication is done by passing messages to run events in those threads.
So what if we pre-created a number of operating system threads, loaded a C level interface to communicate with a database and then passed a script for the threads to evaluate in their event loop. That script would create strings of data for parameters and then either run SQL statements or call databases stored procedures? That is exactly what HammerDB does. In this scenario we have true multithreading and linear scalability. When our benchmarking client has multiple cores and threads we can take advantage of them and run entirely in parallel ensuring a true concurrent workload on the database server. Of course if the threads need to communicate they can through messages in a thread safe way, so for example if you press the stop button in HammerDB you send a message to all Virtual Users to end the current running workload and exit the thread. When you create Virtual Users in HammerDB you can see that you have created threads as follows. (run this command in the console or in the CLI).
puts [ thread::names ] tid000000000000360C tid0000000000000944 tid00000000000032A8 tid0000000000002E10 tid00000000000019E4 tid0000000000001B38 tid0000000000002E80 tid00000000000004F4 tid00000000000006D0 tid0000000000003C44 tid0000000000002CF4
There is one small exception to this parallelism. Of course, you can only update a graphical user interface with the main application thread and therefore any output to be displayed must be sent via a message to this main application thread. Therefore, the Test workload in HammerDB that prints the output from all user sessions requires every session to pass its output to the main display. For this reason the Timed workload suppresses output unless there is an error.
Bytecode Execution
So as we saw in Python ‘it is only in multithreaded programs that spend a lot of time inside the GIL, interpreting CPython bytecode, that the GIL becomes a bottleneck.’ so lets see what happens in HammerDB. Running a performance profiling tool such as perf in Linux we can see that the top event is TEBCresume standing for Tcl Execute Byte Code.
Samples: 67K of event 'cycles:ppp', Event count (approx.): 33450114923
Overhead Shared Object Symbol
33.56% libtcl8.6.so [.] TEBCresume
7.68% libtcl8.6.so [.] Tcl_GetDoubleFromObj
6.28% libtcl8.6.so [.] EvalObjvCore
6.14% libtcl8.6.so [.] TclNRRunCallbacks
It is not a coincidence that as a Tcl proc is compiled to bytecode, HammerDB implements the calling of the database stored procedures as procs. You can see the bytecode generated with a command such as follows.
puts "bytecode:[::tcl::unsupported::disassemble proc slev]"
with output such as the following for the SQL Server slev stored procedure we saw earlier.
bytecode:ByteCode 0x00000211562A4AA0, refCt 1, epoch 17, interp 0x00000211560F30D0 (epoch 17)
Source
set threshold [ RandomNumber 10 20 ]
if {[catch {se… Cmds 21, src 514, inst 314, litObjs 14, aux 0, stkDepth 8, code/src 0.00 Proc 0x0000021155F1E060, refCt 1, args 4, compiled locals 8
slot 0, scalar, arg, slev_st
slot 1, scalar, arg, w_id
slot 2, scalar, arg, stock_level_d_id
slot 3, scalar, arg, RAISEERROR
slot 4, scalar, threshold
slot 5, scalar, message
slot 6, scalar, resultset
slot 7, scalar, slrows
...
So lets look at the slev proc before disassembly. We are calling the stored procedure with the warehouse id and stock level district id parameters, setting the threshold, executing the stored procedure on the database and fetching the results.
#STOCK LEVEL
proc slev { slev_st w_id stock_level_d_id RAISEERROR } {
set threshold [ RandomNumber 10 20 ]
if {[catch {set resultset [ $slev_st execute [ list st_w_id $w_id st_d_id $stock_level_d_id threshold $threshold ]]} message ]} {
if { $RAISEERROR } {
error "Stock Level : $message"
} else {
puts "Stock Level : $message"
}
} else {
if {[catch {set slrows [ $resultset allrows ]} message ]} {
catch {$resultset close}
if { $RAISEERROR } {
error "Stock Level Fetch : $message"
} else {
puts "Stock Level Fetch : $message"
}} else {
catch {$resultset close}
}
}
}
As seen before the application logic and our workload is on the database. Our Virtual User is generating and passing strings of data to call these stored procedures meaning the client logic is exceptionally lightweight. Not only is it lightweight but as we have seen each Virtual User is an operating system thread running compiled bytecode generating strings so not only is it lightweight and parallel it is also very fast. But let’s quantify fast by running the same calculation in SQL Server (see the HammerDB documentation for the Oracle example)
USE [tpcc]
GO
/ Object: StoredProcedure [dbo].[CPUSIMPLE] Script Date: 25/02/2021 17:41:35 /
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[CPUSIMPLE]
AS
BEGIN
DECLARE
@n numeric(16,6) = 0,
@a DATETIME,
@b DATETIME
DECLARE
@f int
SET @f = 1
SET @a = CURRENT_TIMESTAMP
WHILE @f <= 10000000
BEGIN
SET @n = @n % 999999 + sqrt(@f)
SET @f = @f + 1
END
SET @b = CURRENT_TIMESTAMP
PRINT 'Timing = ' + ISNULL(CAST(DATEDIFF(MS, @a, @b)AS VARCHAR),'')
PRINT 'Res = ' + ISNULL(CAST(@n AS VARCHAR),'')
END
Timing = 7767
Res = 873729.721235
(1 row affected)
Completion time: 2021-02-25T17:40:16.1261747+00:00
and in Tcl Bytecode.
proc runcalc {} {
set n 0
for {set f 1} {$f <= 10000000} {incr f} {
set n [ expr {[::tcl::mathfunc::fmod $n 999999] + sqrt($f)} ]
}
return $n
}
puts "bytecode:[::tcl::unsupported::disassemble proc runcalc]"
set start [clock milliseconds]
set output [ runcalc ]
set end [ clock milliseconds]
set duration [expr {($end - $start)}]
puts "Res = [ format %.02f $output ]"
puts "Time elapsed : [ format %.03f [ expr $duration/1000.0 ] ]"
hammerdb>source runcalc.tcl
Res = 873729.72
Time elapsed : 3.553
hammerdb>
So on the same test system SQL Server completed the T-SQL calculation in 7.7 secs and Tcl completed the calculation in 3.5 secs. So for this example the client language is 2X faster than one of the fastest server languages. Yet remember the client logic is only generating strings to call the server side stored procedures (or SQL statements for TPROC-H) and all the Virtual Users are running independently of each other meaning that the client side of the workload is minimal compared to the database side.
As HammerDB tests multiple databases we also have the insight into client performance from comparing and contrasting the throughput from both commercial and open source databases. Consequently, we know that when we see a result for a highly tuned commercial database that is more than 10X higher throughput than a comparative database on the same hardware system we have 100% confidence that the limitation does not reside in the HammerDB client side of the test but instead in the database.
What about Coroutines?
We have seen that for database benchmarking it is important that our Virtual Users run in parallel meaning that each Virtual User should operate as an operating system thread. However, there is one scenario where you could raise an objection. What about when we want to run thousands of database sessions? In this scenario it would not be possible to run thousands of operating system threads due to the overhead on system resources and therefore couldn’t we run an implementation using coroutines instead? The answer is yes and when we want to run thousands of database sessions this is exactly what HammerDB does.
proc promise::async {name paramdefs body} {
# Defines an procedure that will run a script asynchronously as a coroutine.
This option is chosen when you select the Asynchronous Scaling checkbox. You define the number of Virtual Users (operating system threads) and the number of clients per Virtual User sessions managed with coroutines. However, when you select Asynchronous Scaling note that it also activates keying and thinking time for you, this is not coincidental.
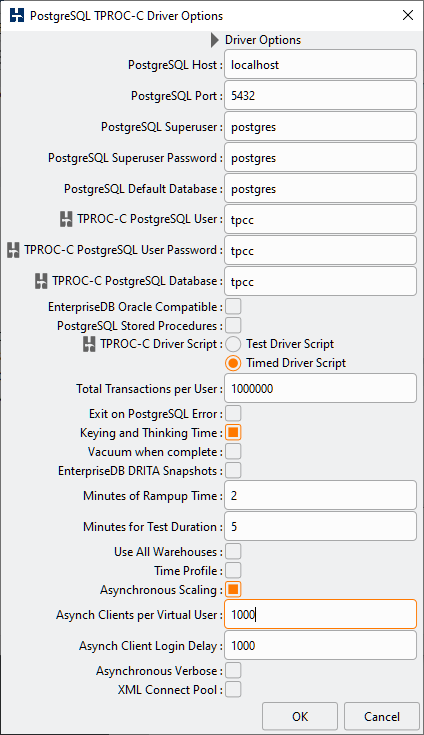
A coroutine implementation is appropriate for managing many sessions concurrently (rather than in parallel) when there is a clear and defined time delay between transactions per session. This is why HammerDB uses threads for Virtual Users for maximum throughput and threads and coroutines for asynchronous scaling when sessions will sleep for keying and thinking time. Coroutines alone would not enable the parallelism required for maximum throughput.
Building a GUI with Tk
HammerDB can run in command line mode but has always had a GUI that runs on both Linux and Windows platforms. For most Python applications the graphical interface used is called Tkinter which is the Python interface to Tcl/Tk. HammerDB bypasses this interface and uses Tk directly meaning that all the features available to a Tkinter application are also available to HammerDB but also more as well, meaning for example that HammerDB could take advantage of SVG graphics for high definition displays before a Python Tkinter application could, creating a native display for both Linux and Windows.
Summary
We have discussed why HammerDB is written in the programming languages it uses and why running the clients in parallel in operating system threads is so important when we want to test concurrency on the database being tested. We have seen that the workloads are written in SQL and stored procedures and the client logic is compiled into Bytecode for performance. All of this is wrapped in an application interface that is simple and intuitive so all you need to do is point HammerDB at your database and start testing.