
If you are new to running Oracle, SQL Server, MySQL and PostgreSQL TPC-C workloads with HammerDB and have needed to investigate I/O performance the chances are that you have experienced waits on writing to the Redo, Transaction Log or WAL depending on the database you are testing. This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment.
Note that the parameters in this article do have the potential to cause data loss if implemented on your production database without full understanding so ensure that you have read this post in its entirety before applying the settings to your environment.
Logging Waits
Firstly we’ll take a look at why these log waits are so important to database performance in an OLTP environment. The diagram below shows a much simplified way how the I/O in a typical relational database operates.
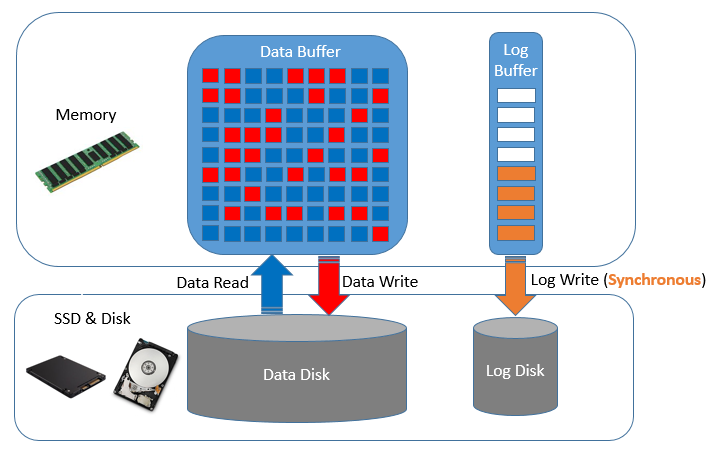
Before the database is started your data should be in a consistent state on disk. When the database is started a component of the in-memory database instance is the data buffer. As data is requested (depending on the type of read), data blocks will be fetched and stored in-memory in this buffer, show in-blue. Over time your workload will modify this data, shown in-red, however these changed data blocks or pages are not written back to the data disk immediately. In fact a single block or page may be modified in-memory multiple times before it is eventually at some point in-time written back to the data disk. In contrast to many people’s understanding of a traditional database against an “in-memory” database it is likely that if the buffer is large enough most of the data you are operating on remains in-memory for the duration of a HammerDB OLTP test. Therefore you are likely to see a spike of reads at the start of the test (this is why there is ramp-up time) and then potentially depending on your configuration the data disk can be relatively quiet for the duration of the test while periodically seeing write activities related to checkpoints (which will be discussed later).
However it should be clear that in the case of a failure such as a crash of the database all of the data in-memory would be lost. Therefore you have the redo, transaction or write-ahead log recording all of the changes to the database. Typically we will see a constant stream of write activity to this disk with no (or minimal) read activity. If there is a failure of the database, subsequently on startup this log will be used to recover the data on the data disk up to the point of the most recent transaction (or the chosen recovery point) i.e. replaying all of those changes in-memory that we lost. To recover right up to the most recent point those writes to the log needed to be synchronous i.e. when a transaction is committed the session waits until the database has confirmed that the changes have been recorded to the log before continuing work. Note that this does not mean that the log is only written at the time of a commit, changes will be streamed into an in-memory log buffer and written to the log disk constantly however once a transaction is committed the user sessions will wait until this log write is confirmed. This wait by the session is what is typically seen as a log wait. Bear in mind that writing to the log takes CPU, it will be a log writing thread or process that needs CPU time to be scheduled to be active, it also requires memory for the log buffer and finally disk for the log itself, therefore this log wait is more than just the disk component. Additionally for the log disk component it is latency for an individual write that is crucial rather than the total I/O bandwidth.
As HammerDB supports graphical metrics for Oracle, this provides the best illustration however the concepts apply in general terms to all databases.
Oracle Log File Sync
The following example takes a snapshot of Oracle metrics showing 3 spikes of activity on a consumer level PC running Oracle within a Virtual Box VM for illustration purposes.The database has been created with the default redo log configuration which is 2 redo logs of 200MB in size each. The first example shows a data load, the second a TPC-C based workload with 5 virtual users and the 2nd example with 10 virtual users.
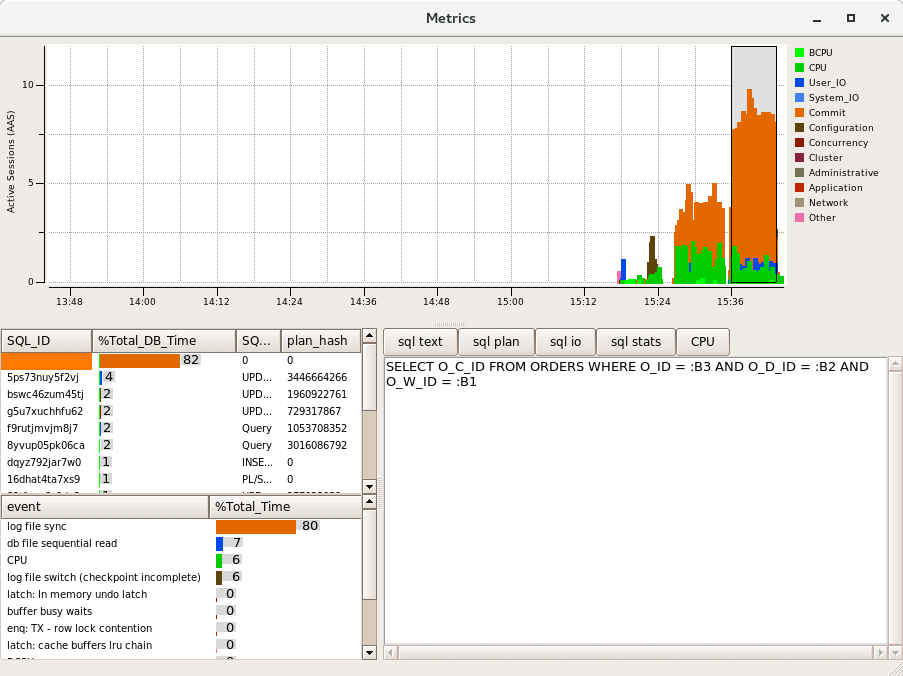
What can be seen fairly quickly is that the dominant colour is orange and the majority of database time is spent on “log file sync”, waiting for these synchronous writes to the redo log. As the activity is increased with the 2nd run performance is not improved, instead the database is spending more time waiting for the redo log.
To illustrate the data reads on Oracle we can flush the buffer cache.
SQL> alter system flush buffer_cache; System altered. SQL>
Re-running the same workload we can now see some blue read activity of “db file sequential read” from index reads at the start of the test, Once our data is buffered this read activity is then diminished as the data in memory is sufficient to sustain the workload that is being run by the rate that it is constrained by “log file sync”.
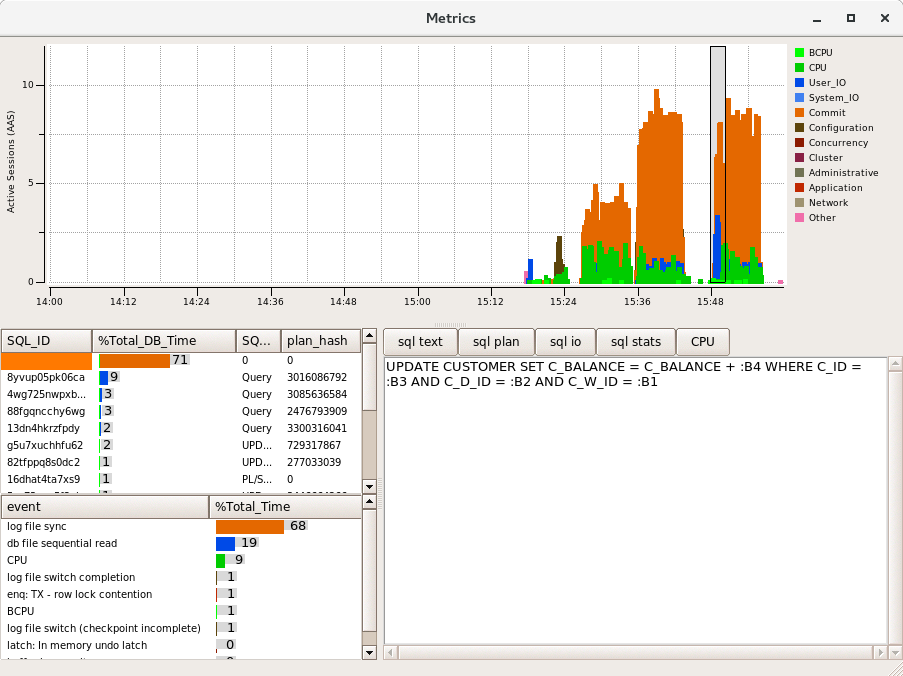
In this scenario the total throughput is considerably lower than the full potential of the system., so what are your options?
Making Logging asynchronous
Clearly the most obvious option is to upgrade your log disk I/O capabilities to be able to sustain writes at the level that the test can produce and if running on a production system, this (and investigating your log size and configuration such as using the right disk sector size is the way to go). However what if in a test environment you cannot upgrade the log I/O but want to move beyond the log bottleneck to be able to test other system components more fully. Fortunately all of the database supported by HammerDB include an option to make the logging asynchronous. In other words we will put our changes in the log buffer, issue a commit but not wait until this is confirmed. Instead we will continue under the assumption that the log write eventually made it to disk. in this scenario it is possible that in the event of a failure data can be lost but for testing purposes it means we can potentially drive much higher levels of throughput than our log disk can typically sustain, showing the system potential if there were a better performing log configuration. Note however that this is not a solution that will make all log related waits disappear. As noted logging also involves CPU and memory and you will still need to make sure all writes reach the disk, the difference is that you are not flushing to disk synchronously on each commit and therefore are aiming to improve throughput by removing this dependency.
Oracle commit_wait and commit_logging
for Oracle the key parameter is commit_wait. By setting this parameter to NOWAIT the session will not wait for the write to be complete, instead continuing its work once the write has been issued. This can be complemented by the parameter commit_logging being set to BATCH which groups the individual writes to be written in larger writes.
| commit_logging | BATCH | |
| commit_wait | NOWAIT |
These parameters can be set as follows:
SQL> alter system set commit_logging='BATCH' scope=spfile; System altered. SQL> alter system set commit_wait='NOWAIT' scope=spfile; System altered.
Having set these parameters and re-run the previous test it can be seen that the wait events are now very different. In particular log file sync as intended has reduced considerably and been replaced by “db file sequential read” as the top event. Why is this the case? Because we have removed the log sync bottleneck we have now increased the throughput and put emphasis on the amount of data in the buffer that is being read-in and written-out at a much greater rate. Consequently we now need to increase the buffer cache in size if we are to see more CPU activity. A good example of how tuning is an iterative process.
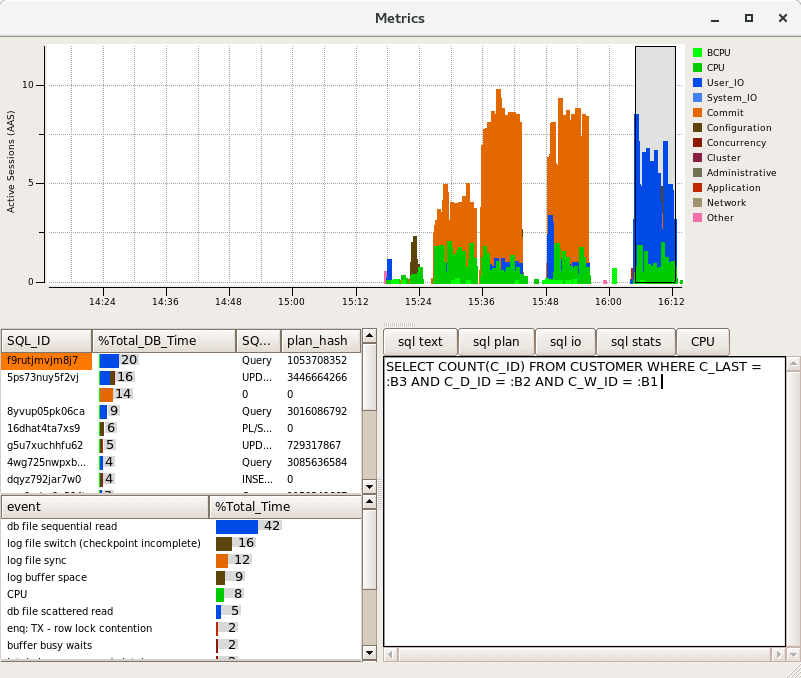
Checkpoint not complete
in the previous diagram we can also see the wait event log file switch (checkpoint incomplete). Returning to the first illustration it was shown that data will be periodically written to disk, at a checkpoint all of the data on disk is up to date with the same point in the log. In this example with the default log configuration of 2 redo logs the database is attempting to switch from one log to the other however the checkpoint operation flushing the data from memory to the data disk has not yet caught up with the previous log and to begin writing to it would overwrite changes on the redo log that correspond to this not yet written yet, consequently the database will wait until this operation has been completed.
2018-11-02T15:38:27.662098+00:00 Thread 1 advanced to log sequence 1402 (LGWR switch) Current log# 1 seq# 1402 mem# 0: /home/oracle/app/oracle/oradata/VULCDB1/onlinelog/o1_mf_1_fjj87ghr_.log 2018-11-02T15:39:25.628040+00:00 Thread 1 cannot allocate new log, sequence 1403 Checkpoint not complete Current log# 1 seq# 1402 mem# 0: /home/oracle/app/oracle/oradata/VULCDB1/onlinelog/o1_mf_1_fjj87ghr_.log 2018-11-02T15:39:29.360911+00:00 Thread 1 advanced to log sequence 1403 (LGWR switch) Current log# 2 seq# 1403 mem# 0: /home/oracle/app/oracle/oradata/VULCDB1/onlinelog/o1_mf_2_fjj87gjj_.log
As can be seen this has happened on a consumer PC configuration with the default redo configuration, therefore for higher throughput also ensure that you resize the logs accordingly.
SQL Server DELAYED_DURABILITY
For SQL Server the equivalent parameter for asynchronous logging is set as follows for the parameter DELAYED_DURABILITY
ALTER DATABASE … SET DELAYED_DURABILITY = { DISABLED | ALLOWED | FORCED } On the same test system it can be seen that without setting this parameter, Logging is shown as the top resource wait.
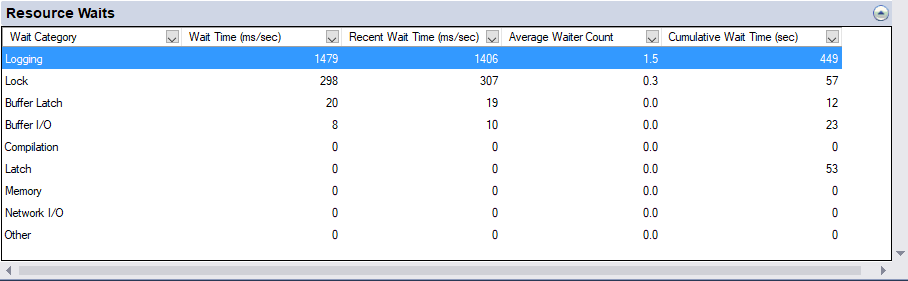
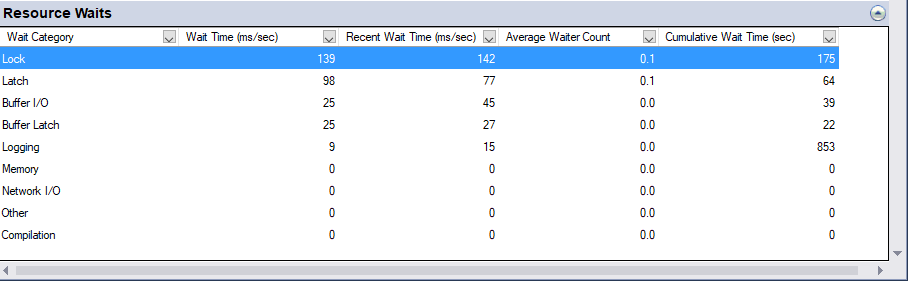
After setting ALTER DATABASE TPCC SET DELAYED_DURABILITY = FORCED it can be seen that the waits on logging are reduced.
MySQL
For MySQL the dependency is at the storage engine level and in this case for the InnoDB storage engine the parameter is self-explanatory.
innodb_flush_log_at_trx_commit=0
PostgreSQL
Similarly for PostgreSQL logging can be set by setting synchronous_commit to off.
synchronous_commit = off # synchronization
Summary
This post aims to address what is the most common scenario for someone running HammerDB TPC-C OLTP workloads for the first time when seeing waits on logging disks and what parameters can be set in a test based environment to achieve more throughput and observe what performance potentially could be achieved without a log disk bottleneck.